
Multi-Task Optimization in Neural Networks: Theory and Practice
Scalarization, learnable loss weights, gradient surgery, Pareto frontiers, and why nothing can beat mathematical theory


Welcome to this week’s issue of Machine Learning Frontiers! Here are recent issues you may have missed:
Multi-Task Learning in Recommender Systems: Challenges and Recent Breakthroughs
A Tour of the Recommender System Model Zoo (Part I, Part II)
The multi-task learning paradigm - that is, the ability to train neural networks on multiple tasks at the same time - has been enormously useful in practical ML applications: it allows us to build a single model where previously we would have needed multiple.
This not only saves cost and makes lives simpler (fewer models that need to be maintained, re-trained, tuned, and monitored), it can also help with performance, as we’ve seen in auxiliary learning, where we add new tasks with the sole purpose of “helping” the main tasks.
How do we optimize such multi-task learners? Is standard gradient descent enough, or do we need additional tricks? This week, we’ll take a closer look into the domain of multi-task-optimization (MTO). We’ll learn about:
Pareto frontiers: how we evaluate the quality of a solution when we optimize for multiple tasks at the same time,
scalarization: the mathematical theory of multi-task optimization, and why it guarantees Pareto-optimality,
learnable loss weights: learning task weights based on modeling uncertainty, and
gradient “surgery” and related algorithms: resolving conflict between competing tasks by manipulating their gradients directly.
Let’s get started.
Scalarization (2004, at least)
Scalarization is Mathematic’s answer to the multi-task optimization problem. In a multi-task model we are trying to learn K tasks, such as predicting “click”, “add-to-cart”, and “purchase” in an e-commerce recommender system. (In fact, modern recommender systems may include more than a dozen tasks!) In such a setting, we can define the solution as the one that minimizes

that is, the weighted sum of task-specific losses, where the weights are larger than 0 and sum up to 1.
This trick of reformulating a multi-task learning problem as single optimization problem is known as scalarization, and it’s borrowed from the broader discipline of mathematical optimization, which is covered in textbooks such as Boyd & Vandenberghe.
An important definition in such a problem is that of Pareto optimality: a solution θ is said to be Pareto-optimal if it achieves the lowest loss for all tasks, that is, there is no θ with a lower loss for any of the tasks. Usually, there is no single solution θ that’s Pareto-optimal, but instead multiple, forming a high-dimensional curve in the loss space — the so-called Pareto frontier.
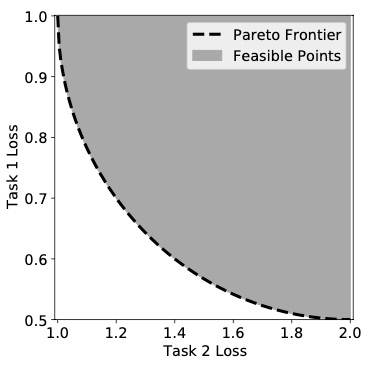
Which brings us to an important mathematical result: mathematically, it can be proven that no matter which combinations of weights we pick, we always end up with a solution θ that’s sitting on the Pareto frontier. All we need to do in a practical application is to sweep over all possible weight combinations and pick the one that’s best aligned with what we want to achieve.
The story of multi-task optimization could end here. Mathematically, there’s nothing more to say about the problem. Practically, however, things are very different: in practice, we may not have near enough resources, both in time and in hardware, to search over the loss weights. This is particularly true if the number of tasks grows very large, such as in modern recommender systems.
Hence, the need for some more practical tricks. Here, let’s take a look at 2 of them: learnable loss weights and gradient surgery.
Learnable loss weights (2018)
‘Learnable loss weights’ (Kendall et al 2018) was introduced in 2018 in a paper by researchers from the University of Cambridge to help solve multi-task computer vision problems. Multi-task problems are common in CV: an autonomous driving application, for example, needs to be able to detect objects (including people, other cars, bicycles, etc), estimate depths, detect traffic signs, detect lanes, and so on.
The key idea in LLW is to automatically assign task-specific loss weights that are inversely proportional to the model uncertainty for the particular prediction for that task. The intuition is that if the model is wrong but uncertain we should assign a smaller loss compared to when the model is wrong and certain: we want to nudge the model more in the latter case than in the former.
Mathematically, this means that we minimize

where L_i is the loss for task i and σ_i is the uncertainty in the predictions for task i. The last term in the loss, which is simply adding the log of the uncertainties themselves, nudges the model to make predictions with high certainty instead of simply predicting every possible outcome with a small degree of certainty. For more than 2 tasks, we simply add more terms to this equation, one for each task’s loss.
Theoretically, this makes a lot of sense, but how to estimate the uncertainties σ_i? Practically, this can be done comparing the predictions to the ground truth and fitting a Gaussian function N to that distribution, where the mean is the prediction itself and the standard deviation is the model uncertainty, i.e. the quantity that we’re looking for:

In the Cambridge paper, the authors apply learnable loss weights to a multi-task object detection problem, where the individual tasks are semantic segmentation, instance segmentation, and depth prediction. Compared to uniform weights (1/3, 1/3, 1/3), with learnable loss weights (which turned out to be 0.89, 0.01, 0.1) the resulting segmentation has a 13% better IoU (“intersection over union”, a quality measure in object detection), proving the effectiveness of this approach.
Of course, it needs to be said that a comprehensive enough parameter sweep would have found the same minimum (0.89, 0.01, 0.1) and yielded the same results - but then again, parameter sweeps are costly, both in terms of time and resources, and that’s precisely the advantage of LLW: it’s parameter-free!
Gradient “surgery” (2020)
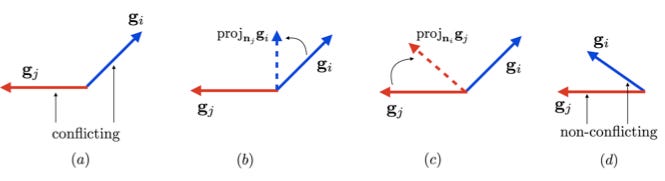
Let’s recap for a moment. Scalarization guarantees a Pareto-optimal solution, however in order to find the best solution for a particular application we need to sweep over the weight parameters, which can be very costly. LLW solved this problem by tuning the loss weights heuristically, using model uncertainty.
However, there’s another way we can get around manual tuning of loss weights, and that’s by directly manipulating the gradients of tasks that are being learned, which brings us to the Trick 2, which we broadly call “gradient surgery” and related algorithms.
Gradient surgery, also known as PCGrad (“projecting conflicting gradients”), was proposed in a 2020 paper from a collaboration of researchers from Stanford University, UC Berkeley, and Google Robotics. The key idea in the algorithm is to resolve conflict between competing gradients (i.e., gradients that pull the model in opposing directions) by projecting the gradient from one task onto the normal plane of the other, alternating the gradient that’s being changed at each training step. PCGrad is model-agnostic: it can be applied to a range of problem settings, including multi-task supervised learning and multi-task reinforcement learning, both of which the authors consider in the paper.

The authors evaluate PCGrad on several datasets, including MultiMNIST, CityScapes, CelebA, multi-task CIFAR-100, and NYUv2. They compare PCGrad against the baseline of single-task learning (one model per task) as well as a suite of competing methods, in particular STAN, Split, Wide&Deep, Dense, Cross-Stitch, and MTAN.
The result? PCGrad demonstrates substantial improvements in terms of data efficiency, optimization speed, and final performance compared to these other approaches, including single-task learning. For example, the paper reports a more than 30% absolute improvement on a multi-task reinforcement learning problem when using PCGrad compared to single-task learning methods.
In addition to PCGrad, several other gradient manipulation algorithms have been proposed, such as:
GradNorm, in which we normalize the scale of all gradients to be identical to the average gradient scale (averaged over all tasks) at each training iteration,
GradSimilarity, in which we only consider gradients of other tasks that have a positive cosine with respect to the anchor gradient (i.e. the gradient from the main task we want to learn), and
MetaBalance, in which we normalize the scale of all gradients to be identical to the scale of the anchor gradient (a similar algorithm is MTAdam).
And there are more, as you can see in this screenshot from ConnectedPapers (with the Gradient surgery paper highlighted in red):

Conclusion - does MTO really work?
Time for a recap. Mathematically, it can be shown that all we need to do in a multi-task problem is to apply scalarization and sweep over the loss weights in order to find a point that’s most aligned with what we’re trying to achieve. This approach is (provably!) Pareto-optimal.
While learnable loss weights, gradient surgery and related algorithms are useful practical tricks that circumvent tuning these loss weights, it’s important to remember that, mathematically, they cannot beat scalarization!
This fact has been demonstrated clearly in the 2022 Google paper “Do Current Multi-Task Optimization Methods in Deep Learning Even Help?”. In this comprehensive work, the authors compare the predictive performance of scalarization + parameter tuning against a suite of modern gradient manipulation algorithms, including Gradient Surgery and GradNorm (which we’ve introduced above), on a multi-task language modeling problem, where the different tasks correspond to different languages.
The result? On a 2-task translation task, where the 2 tasks are translating from English to French and translating from English to Chinese, none of the MTO algorithms they tried where able to beat scalarization with a comprehensive parameter sweep, the Pareto frontier of which is shown in the blue curve below.

The authors explain that the space of solutions obtained by scalarization + parameter sweeps forms a superset of those solutions found by dedicated MTO algorithms, and that therefore, well, scalarization is really all you need. The success of dedicated MTO algorithms, in their view, is simply an illusion of not having tuned the baseline model well enough.
In my own view, the Google paper misses an important point though: the main motivation behind gradient manipulation algorithms such as Gradient Surgery is actually not to beat scalarization, but instead to find a good solution without the need for expensive tuning of the loss weights. This can be particularly useful when the number of tasks, the model size, and the amount of data we train on get very large, too large to allow for comprehensive tuning of the loss weights.
Mathematically, the problem of multi-task optimization has been solved at least since 2004. Practically, we’re only really getting started!
Machine Learning Frontiers is a one-man startup with a mission to open the black box and make modern ML algorithms accessible to anyone. If you support this mission, consider becoming a paid subscriber. (Tip: most universities and tech employers will likely let you expense it!) As a paid subscriber, you’ll also get access to the growing ML Frontiers archive.