
Machine Learning with Expert Models: A Primer
How a decades-old idea allows us to train outrageously large neural networks today


Expert models are one of the most scientifically interesting and practically useful inventions in Machine Learning, yet they hardly receive as much attention as they deserve. In fact, expert modeling does not only allow us to train neural networks that are “outrageously large” (more on that later), they also allow us to build models that learn more like the human brain, that is, different regions specialize in different types of input.
In this article, we’ll take a tour of the key innovations in expert modeling which ultimately lead to recent breakthroughs such as the Switch Transformer and the Expert Choice Routing algorithm. But let’s go back first to the paper that started it all.
Adaptive mixtures of local experts (1991)

The idea of mixtures of experts (MoE) traces back more than 3 decades ago, to the 1991 “Adaptive Mixtures of Local Experts” co-authored by none other than the godfather of AI, Geoffrey Hinton. The key idea in MoE is to model an output “y” by combining a number of “experts” E, the weight of each is being controlled by a “gating network” G:
An expert in this context can be any kind of model, but is usually chosen to be a multi-layered neural network, and the gating network is
where W is a learnable matrix that assigns training examples to experts. When training MoE models, the learning objective is therefore two-fold:
the experts will learn to process the input they’re given into the best possible output (i.e., a prediction), and
the gating network will learn to assign the right training examples to the right experts by learning the matrix W.
Why should one do this? And why does it work? At a high level, there are three main motivations for using such an approach:
First, MoE allows scaling neural networks to very large sizes due to the sparsity of the resulting model, that is, even though the overall model is large, only a small amount of computation needs to be executed for any given training example because of the presence of highly specialized experts. This approach stands in contrast to the standard “dense” neural networks, in which every single neuron is needed for every single input example.
Second, MoE allows for better model generalization with less risk of overfitting because each individual expert can be a relatively small neural network, yet we still achieve strong overall model performance by adding more experts. Much like boosting, it’s a way to combine a large number of relatively weak learners into a single, strong learner.
And third, MoE mimics more closely how our brains work: any given input only activates certain regions in our brains, with distinct regions for touch, vision, sound, smell, taste, orientation, and so on. All of these are, well, “experts”. MoE is a way to mimic this behavior from human intelligence in artificial intelligence.
In short, MoE frees us from the requirement that every single neuron needs to be activated for every single input. MoE models are sparse, highly flexible, and empirically powerful.
Outrageously large neural networks (2017)
Fast-forward 26 (!) years to the highly influential paper “Outrageously large neural networks”, again from Hinton’s team, this time at Google Brain. In this work, the authors take MoE to its limits, presenting a 6 Billion parameter MoE model with thousands of experts. In order to build such an “outrageously large” (as they call it) MoE model, the authors introduce several modeling tricks, including:
Noisy top-k gating. Top-k gating simply means that for each training example we only run a forward pass through the top k experts, which are determined by the gate, and ignore all of the other experts. This saves computational cost: for example, if we have 1000 experts and apply top-k gating with k=5, we’d cut down the total computational cost of training the model by a factor of 200! Out of all of the innovations in MoE, Top-k gating (which has also become known as “sparse gating”) has been the most pivotal.
“Noisy” means that we’re adding tunable Gaussian random noise to the gating values. The authors find that this noise helps with load balancing, that is, making sure an entire batch of data is not being sent to a single expert.
Auxiliary losses. The authors add two auxiliary (regularizing) loss terms to the model’s loss function, “load balancing loss” and “expert diversity loss”, each with its own tunable regularization parameter:
Load balancing loss is proportional to the coefficient of variation in the number of training examples received by each expert. Adding this loss improves computational performance because it prevents the introduction of “expert bottlenecks” where all training examples have to pass through one expert. (One subtlety is that the number of training examples per expert is not differentiable — so the authors introduce a smooth approximation of that number instead.)
Expert diversity loss is proportional to the coefficient of variation of expert importances, where expert importance is defined as the sum of the gate values for that expert, that is
\(I_e = \sum_i G_e(x_i)\)where the sum is taken over all training examples in the batch. Adding this loss nudges the model to utilize all of the experts at least some of the time, instead of simply sending all training examples to a single expert that learns everything.
While these two loss terms are similar, the authors find the best overall performance when adding both load balancing loss and expert diversity loss (both scaled with a “regularization factor” of 0.1).
Customized parallelism. The authors show that large MoE models benefit from a customized combination of data parallelism and model parallelism: in particular, we can allow for experts to be distributed across machines because we don’t require communication between them, while at the same time using data parallelism in order to increase the batch size. This form of parallelism allows us to massively scale up the MoE model: in their experiments, the authors scale it up to 6 Billion parameters with thousands of experts.
Using their massive MoE model, the authors establish a new SOTA on the Billion-words language modeling benchmark.
Switch Transformers (2022)
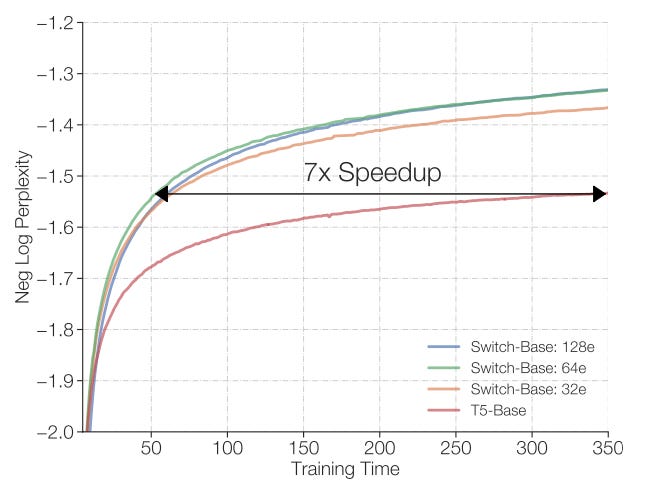
While “Outrageously large neural networks” demonstrated the usefulness of noisy top-k gating in MoE models, Switch Transformers, also by Google, brought it to its extreme conclusion by building MoE Transformer models with k=1, that is, each training example is only being sent to a single expert. The authors call this “hard routing”, in contrast to the “soft routing” in standard MoE models where the output from multiple experts is being combined.
Practically, hard routing (k=1) means that we can have N>1 experts, with any number N, and constant computational complexity: the model capacity scales as O(1)! The trade-off is that we need a huge amount of memory to store all of the experts. However, since we require no communication between experts, that memory can be distributed across a large cluster of machines.
In addition, the authors introduce a number of practical modeling tricks, including:
precision casting: this means that we send weights in between machines in BF16 (16-bit brain float) but cast them to FP32 (32-bit floating point precision) when computing the gating values. This trick minimized communication overhead because we only need to communicate 16 instead of 32 bits, while at the same time ensuring that the softmax computation is stable (which it isn’t with 16 bits).
aggressive expert dropout: the authors find that they can improve the performance of the model by applying aggressive dropout of 0.4 within the expert modules, while keeping dropout in the rest of the model architecture at a smaller rate of 0.1. The reasoning is that experts overfit more easily because they only see a fraction of the data, and therefore need to be regularized more heavily.
scaled expert initialization: the authors find much better training stability when scaling the initialization of the expert layers down by a factor of 10.
Ultimately, the authors end up with a Switch Transformer model that can be pre-trained 7x faster compared to Google’s T5 language model with the same computational resources - one of the first demonstrations of the power of scaling up model capacity with MoE.
Expert Choice Routing (2022)

One of the most recent breakthroughs in expert modeling is “Expert choice routing”, yet another innovation by Google.
The problem with training MoE models is that experts often remain under-utilized because of the “winner-take-all” effect, where a single expert that randomly receives the first few training examples rapidly becomes much better than the other experts and ends up dominating the gate. So far, the standard practice has been to add auxiliary losses which nudge the model to utilize all of the experts equally (such as expert diversity loss in Hinton’s work). However, adding auxiliary losses introduces the problem of tuning their regularization parameters relative to the actual loss we want to minimize: too small, and there’s no change in the model behavior at all, too large, and we risk making all experts identical (another local minimum).
The key idea in “expert choice routing” is simple yet powerful: let expert choose their top k training examples within a batch, instead of having a training example choose its top k experts. This has several advantages:
it guarantees perfect load balancing with equal expert utilization (each expert always gets the same number of training examples in each batch),
not every training example ends up with the same number of experts, some of them may be routed to 1 experts, and some of them to all experts. This is a desired property: different training examples represent different degrees of difficulty for the model, and consequently may require a different number of experts,
no need for adhoc auxiliary losses that need to be tuned.
Mathematically, expert choice routing replaces the standard gating function
with
that is, instead of an e-dimensional vector, the gate G is now a matrix with dimensions e (the number of experts) times n (the number of tokens). (Why tokens? The authors consider NLP problems, hence each training example is simply a sequence of n possible tokens.)
So far for the theory, but how well does it work in practice? The authors show that they can achieve the same performance as the Switch Transformer in half the training time, and for the same computational cost, they beat the Switch Transformer on 11 tasks from the GLUE and SuperGLUE benchmarks!
Expert Choice Routing beat the Switch Transformer, which showed that, at least for NLP problems, “expert choice” is superior to “token choice”.
Summary
A quick recap:
the key idea in MoE models is to model the output y as a weighted sum of experts, where each expert is simply a small neural network itself, and the weights are determined by
G(x) = softmax(Wx), where W is a learnable matrix.Top-k gating (aka sparse gating) means that we ignore all experts except for the top k, as determined by the gate. In the extreme case of
k=1, this allows us to scale up any model with O(1) computational complexity!MoE models often get stuck in a local minimum where all training examples are simply being sent to a single expert. A remedy is to add “expert diversity loss” to the model’s loss function.
Switch Transformers sparse gating with Transformer models, and showed that this combination allows training the T5 language model 7x faster.
Expert Choice Routing introduced the idea of having experts choose their own training examples instead of the other way around. Expert Choice Routing beat the Switch Transformer on GLUE and SuperGLUE!
And this is just the tip of the iceberg. Expert modeling is an exciting domain that has been decades in the making, and we’re just starting to see its impact on modern Machine Learning applications such as natural language processing and recommender systems. Watch this space - new breakthroughs are certainly on the horizon!
Thank you for reading Machine Learning Frontiers! If you like this content, please make sure to subscribe! This story has a Part II here: