
Towards Understanding the Mixtures of Experts Model
What exactly happens under the hood when we train MoE models?


Mixtures of Expert (MoE) models have a long history, spanning almost 3 decades of research. Recently, sparse MoE models - where only the top expert is running a forward pass over the data - have been used to scale deep learning models with O(1) computational complexity, leading to breakthroughs such as Google’s Switch Transformer.
However, surprisingly little is known about why exactly MoE works in the first place. When does MoE work? Why does the gate not simply send all training examples to the same expert? Why does the model not collapse into a state in which all experts are identical? How exactly do the experts specialize, and in what? What exactly does the gate learn?
Luckily, research has started to shed some light into these questions. Let’s take a look.
MoE models - a lighting primer
(This is going to be high-level only - check out my previous post for more details.)
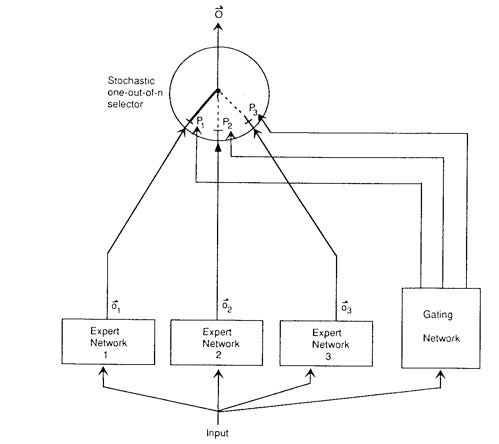
As a brief reminder, MoE was invented in the 1991 paper “Adaptive Mixtures of Local Experts”, co-authored by none other than the godfather of AI himself, Geoffrey Hinton. The key idea in MoE is to model an output y given an input x by combining a number of “experts” E, the weight of each is being controlled by a “gating network” G,
where the gating network G is given a simple linear model,
where W is a learnable matrix that assigns training examples to experts. When training MoE models, the learning objective is therefore two-fold:
the experts will learn to process the input they’re given into the best possible output (i.e., a prediction), and
the gate will learn to “route” the right training examples to the right experts, that is, learn the routing matrix W.
MoE has been shown to be particularly powerful when we run the computation over just the single expert with the largest gating value, that is, we approximate y as
where I is the index of the maximum value of G. We call this “hard routing” or “sparse gating”, and it has been the key technique behind breakthroughs such as the Switch Transformer: it allows us to scale models with a computational complexity of O(1)!
With that background, let’s next take a look at a few particular use-cases and what the experts actually learned.
MoE in vowel discrimination
In order to get a better understanding of what exactly the experts are learning, let’s first go back to the original 1991 MoE paper, which indeed has some clues. Here, the authors build a 4-expert MoE model on a vower discrimination task, that is, distinguish [A] from [a] and [I] from [i] in voice recordings.
The following plot shows their data (i and I in the top left, a and A in the bottom right) as a function of formant values (acoustic features that describe the sound of the vowel):
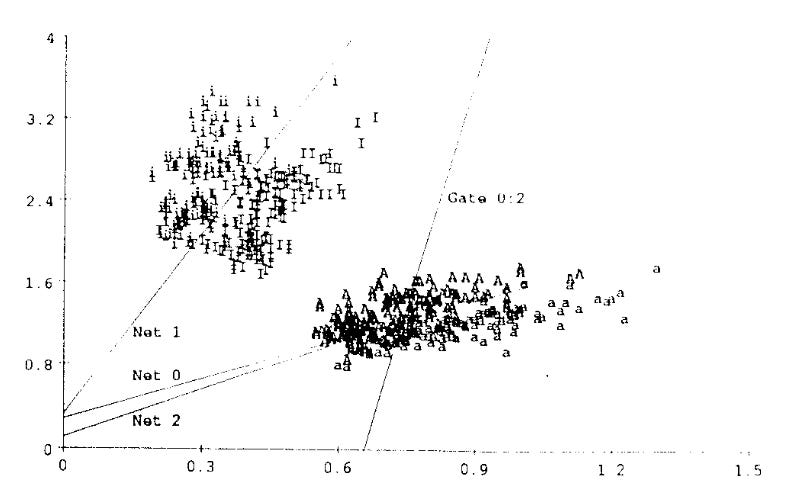
How to read this plot:
The “points” plotted are the data: i, I, a, and A. (It’s a little hard to read because this is an old paper.)
The lines “Net 0”, “Net 1”, and “Net 2” show the decision boundaries that are learned by 3 of the 4 experts. What about the 4th expert? The authors report that it failed to learn any useful decision boundary!
The line “Gate 0:2” shows the gate’s decision boundary between sending inputs to expert 0 (to left) vs expert 2 (to the right).
See what’s happening here? Expert 1 specialized in discriminating [i] from [I], while both experts 0 and 2 specialized in [a] vs [A], probably because that data was a bit harder to classify and not as easily separable as [i] vs [I].
The take-away: the gate learns to cluster the data, and the experts learn the decision boundaries within a cluster. More difficult regions of the data will end up with more experts allocated to them. Some experts, though, may bring not much to the table.
MoE in translation
Let’s consider another example that demonstrates pretty well what the experts are actually learning. This examples comes from the 2017 paper “Outrageously large neural networks”, again from Hinton’s lab, this time at Google Brain.
Here, the authors apply MoE to a natural language problem: translation of sentences from English to French. Technically, they add an MoE layer with 2048 experts in between a stack of 2 LSTM modules, hypothesizing that different experts would end up specializing on different kinds of inputs.
And indeed, that’s what appears to be happening. The following table lists the top input tokens, ranked by gate value, for 3 of the 2048 experts:

Again, we see the same sort of clustering behavior that we’ve seen earlier: Expert 381 specializes in a word cluster spanned by words like “research”, “innovation”, science”, while Expert 2004 specializes in a word cluster spanned by words like “rapid”, “static”, “fast”, and so on.
And again, just like in the previous example, there’s at least one expert that doesn’t appear to add much to the table, Expert 752, which (who?) exclusively looks at the token “a”.
This is fascinating behavior: we didn’t teach the model that these are related words, nor did we ask the model cluster words, nor did we specifically allocate experts to certain words. All of this is emerging behavior, and the only things that we specified ahead of time were the number of experts and the learning objective.
MoE in synthetic data
Finally, let’s take a look at a very recent paper that did a lot to help understand what happens inside the MoE layer, “Towards Understanding the Mixture-of-Experts Layer in Deep Learning” by researchers Zixiang Chen et al from UCLA.
Here, the authors apply a very simple 4-expert MoE model on a synthetic toy dataset consisting of 4 clusters of datapoints that belong to either of 2 classes. The learning objective is simply to separate these classes across all 4 clusters. The experts in this model are 2-layer CNNs with either linear or non-linear (cubic) activation function.
Below is a visualization of what happens during the training process, showing the MoE model with nonlinear activation at the top, and linear activation at the bottom. This graph shows the datapoints consisting of the two classes (crosses and circles), which of the 4 experts the datapoint is being routed to by the gate (yellow, blue, green, red), and the model’s learned decision boundaries (jagged lines).

The take-aways:
Specialization takes time. In the beginning of model training, there’s no specialization at all! All experts are everywhere all over the place. As the training progresses, slowly the clusters get allocated to certain experts.
Expert allocation is random. There is no particular rule as to which clusters get assigned to which expert - it’s random. If you look closely, you see that the top right cluster happens to have a few more datapoints that are being routed to the “blue” expert, and that random perturbation may be the reason that the entire cluster ends up blue.
Non-linear beats linear. Linear experts don’t work as well, as seen by comparing the top right (non-linear) to the bottom right (linear) plot: the decision boundaries from the linear experts aren’t as good, and the clusters are also not as well segregated. This shows that expert non-linearity is one of the keys to make MoE work.
It is also insightful to track the “dispatch entropy” of the gate, which is largest if each expert receives training example from all clusters, and lowest (0) if each expert only receives training examples from a single cluster. As training progresses (from left to right in the plot below), dispatch entropy drops until it reaches a stable point - the point with a near-1:1 correspondence between clusters and experts:

Which is, once again, telling us the same story: the gate learns to segregate the data into clusters, and the experts specialize in their (randomly assigned) clusters.
3 papers, 3 decades, 1 story.
Take-aways
With all that context, let’s revisit - and answer - the questions we asked earlier:
Q: When does MoE work?
A: MoE works best when the data is naturally clustering - we saw that in the vowel problem, the translation problem, and in the synthetic data.Q: Why does the gate not simply send all training examples to the same expert?
A: Because the performance would be bad: a single expert cannot learn each of the cluster’s decision boundaries equally well. And, as in all neural networks, bad performance creates large gradients to pull the model in the opposite way.Q: Why does the model not collapse into a state in which all experts are identical?
A: Again, this is because the performance in this case would be bad: we get better performance when different experts specialize in different regions of the data.Q: How exactly do the experts specialize, and in what?
A: Experts specialize in different regions of the data, and that specialization is random: it depends on the (random) initialization of the gate.Q: What exactly does the gate learn?
A: The gate learns to cluster the data, and to assign each cluster to one (or more) experts.
MoE remains one of the most scientifically interesting and practically useful modeling paradigms in ML, and we’re just starting to see its implications on modern ML applications. Understanding what exactly happens under the hood is a critical step to make them even better.
Have any particular ML topics that you’d like to learn more about? Any questions about ML engineering in practice? Feel free to reply to this Email, and I’ll start answering the top questions in the next issues.
If you enjoy my Newsletter I’d appreciate if you could help spread the word using the Share button below. Until next week!