
A Tour of the Recommender System Model Zoo (Part II)
DeepFM, AutoInt, DLRM, DHEN, and the never-ending race for the best recommendations


Recommender systems are among the fastest-evolving industrial ML applications on the planet today. Better recommendations lead to more users and more conversions, creating all the incentive to create bigger, better, and more complex models.
Last week, we started our tour of the recommender system model zoo, and learned that:
NCF, which stands for "neural collaborative filtering" (He et al, 2017) proved the value of replacing (then standard) linear matrix factorization algorithms with a neural network. With a relatively simply 4-layer neural network, they were able to beat the best matrix factorization algorithms at the time by 5% hit rate on the Movielens and Pinterest benchmark datasets.
Wide & Deep (Chen et al, 2016) demonstrated the critical importance of cross features, that is, second-order features that are created by crossing two of the original features. The Wide & Deep architecture combines a wide and shallow module for cross features with a deep module much like NCF. Compared to a deep-only model, Wide & Deep improved acquisitions in the Google Play store by 1%!
DCN, which stands for "deep and cross neural network" (Wang et al, 2017) showed that we can get even more performance gains by replacing manual engineering of cross features with an algorithmic approach that automatically creates all possible feature crosses up to any arbitrary order. Compared to Wide & Deep, DCN achieved 0.1% lower logloss on the Criteo display ads benchmark dataset.
This week, our tour continues with some of the more recent modeling breakthroughs: let’s dive into DeepFM, AutoInt, DLRM, and DHEN.
DeepFM (Huawei, 2017)

Just like Google’s DCN, Huawei’s, “DeepFM” also replaces manual feature engineering in the wide component of Wide&Deep with a dedicated neural network that learns cross features. However, unlike DCN, the wide component is not a cross neural network, but instead a so-called FM (“factorization machine”) layer.
What does the FM layer do? It’s simply taking the dot-products of all pairs of embeddings. For example, if a movie recommender takes 4 id-features as inputs, such as user id, movie id, actor ids, and director id, then the FM layer computes 6 dot products, corresponding to the combinations user-movie, user-actor, user-director, movie-actor, movie-director, and actor-director. The output of the FM layer is then concatenated with the output of the deep component and passed into a sigmoid layer which outputs the model’s predictions.
(In the figure, you notice a circle marked as “+” in the FM layer in addition to the inner products. Think of this like a skip connection that passes the som of the inputs directly into the output unit)
The authors show that DeepFM beats a host of its competitors, including Google’s Wide&Deep, by more than 0.42% Logloss on company-internal data.
AutoInt (Song et al, 2018)
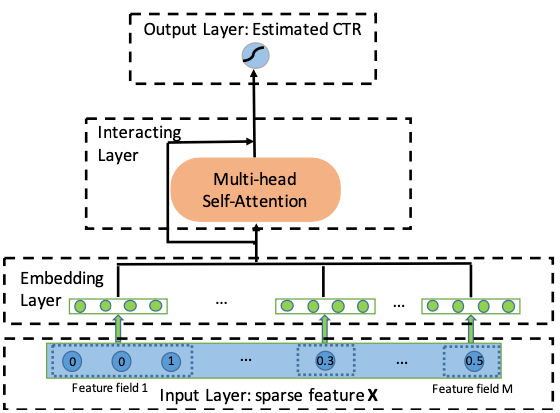
The key idea in DCN and DeepFM was to create feature crosses in a brute-force way, simply by considering all possible combinations. This is not only inefficient, it could also create feature crosses that aren’t helpful at all, and just make the model overfit.
What we need, then, is a way to determine automatically which feature interactions to pay attention to and which to ignore. We need - you’ve guessed it - self-attention!
That was the key insight behind AutoInt, short for “automated feature interaction learning”, proposed by Weiping Song et al from Peking University, China. In particular, the authors first project each individual feature into a 16-dimensional embedding space and then pass these embeddings into a stack of several multi-head self-attention layers that automatically create the most informative feature interactions. The inputs going into the key, query, and value matrices are simply the list of all feature embeddings, and the attention function is simply the dot product, “due to its simplicity and effectiveness” in capturing feature interactions.
This sounds complicated, but really there’s no magic here - just a bunch of matrix multiplications. As a concrete example, here’s the attention matrix that one of the attention heads in AutoInt learns on the MovieLens benchmark dataset:

The model learns that the feature crosses formed by Genre-Gender, Genre-Age, and RequestTime-ReleaseTime are important, which are all marked in green. This makes sense: men usually prefer different movies than women, and kids prefer different movies than adults. What about the RequestTime-ReleaseTime cross feature? It simply encodes movie freshness, at the time of the training example.
Using a stack of 3 attention layers with 2 heads each, the authors of AutoInt were able to beat a host of competitors, including Wide&Deep and DeepFM, on the MovieLens and Criteo benchmark datasets.
DLRM: Interactions are all you need! (Meta, 2019)

Let’s fast-forward by a year to Meta’s DLRM (“deep learning for recommender systems”) architecture, another important milestone in recommender system modeling. The key idea was to take the approach from DeepFM but only keep the FM part, not the Deep part, and expand on top of that. The underlying hypothesis is that sparse features and their interactions are really all that matter in recommender systems. The deep component is not really needed. “Interactions are all you need!”, you may say.
Under the hood, DLRM projects all sparse and dense features into the same embedding space, passes them through MLPs (blue triangles), computes all pairs of feature interactions (the cloud), and finally passes this interaction signal through another MLP (the top blue triangle). The interactions here are simply dot products, just like in DeepFM.
The key difference to the DeepFM’s “FM” though is the addition of all these MLPs, the blue triangles. Why do we need those? Because they’re adding modeling capacity, allowing us to model more complex interactions. After all, one of the most important rules in neural networks is that given enough parameters, MLPs with sufficient depth and width can fit data to arbitrary precision!
In the paper, the authors show that DLRM beats DCN on the Criteo dataset. The authors’ hypothesis proved to be true. Interactions, it seems, may really be all you need.
DHEN (Meta, 2022)
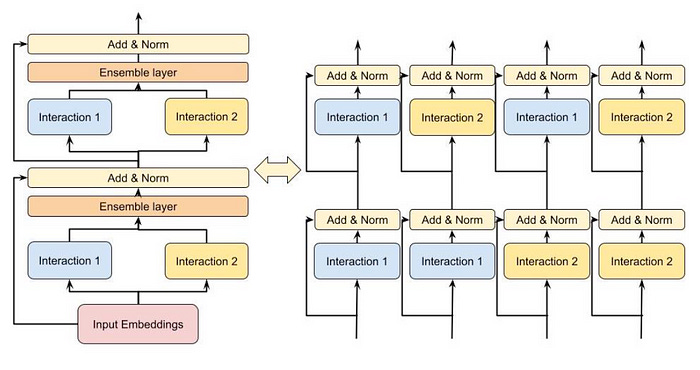
In contrast to DCN, the feature interactions in DLRM are limited to be second-order only: they’re just dot products of all pairs of embeddings. Going back to the movie example (with features user, movie, actors, director), the second-order interactions would be user-movie, user-actor, user-director, movie-actor, movie-director, and actor-director. A third-order interaction would be something like user-movie-director, actor-actor-user, director-actor-user, and so on.
For example, certain users may be fans of Steven Spielberg-directed movies starring Tom Hanks, and there should be a cross feature for that! Alas, in standard DLRM, there isn’t. That’s a major limitation.
Enter DHEN, short for “Deep Hierarchical Ensemble Network”. The key idea is to create a “hierarchy” of cross features that grows deeper with the number of DHEN layers, and so can include third, fourth, and arbitrarily high orders of interactions.
Here’s how DHEN works at a high level: suppose we have two input features going into DHEN, and let’s denote them by A and B. A 1-layer DHEN module would then create the entire hierarchy of cross features including the features themselves up to second order, namely:
A, AxA, AxB, BxA, B, BxB,where “x” is not just a single interaction but stands for a combination of the following 5 interactions:
dot product,
self-attention (similar to AutoInt)
convolution,
linear: y = Wx, or
the cross module from DCN.
Add another layer, and things start to get pretty complex:
A, AxA, AxB, AxAxA, AxAxB, AxBxA, AxBxB,
B, BxB, BxA, BxBxB, BxBxA, BxAxB, BxAxA,where “x” stands for one of 5 interactions, resulting in 62 distinct signals! DHEN is a beast, and its computational complexity (due to its recursive nature) is a nightmare. In order to get it to work, the authors of the DHEN paper even invented a new distributed training paradigm called “Hybrid Sharded Data Parallel”, which achieves 1.2X higher throughput than the (then) state-of-the-art distributed learning algorithm.
But most importantly, DHEN works: in their experiments on internal click-through rate data, the authors measure a 0.27% improvement in NE compared to DLRM, using a stack of 8 DHEN layers. You may question whether such a seemingly small improvement in NE is worth such an enormous increase in complexity - alas, at a scale such at Meta’s, it probably is!
Summary
The key take-aways:
DeepFM replaces the cross neural network in DCN with factorization machines, that is, dot products.
AutoInt introduces the idea of multi-head self attention: instead of simply generating all possible cross features in a brute-force way, we use the attention mechanism to learn which cross features really matter.
DLRM shows that interactions are all you need: it’s a like just using the FM component of DeepFM but with MLPs added before and after the interactions to increase modeling capacity.
DHEN goes not just a step but one giant leap further than DLRM by introducing a hierarchy of feature interactions consisting of dot product, AutoInt-like self-attention, convolution, linear processing, and DCN-like crossing, that replace DLRM’s simple dot product.
And that’s just the tip of the iceberg. Deep Learning in recommender systems is still an active research domain, as evidenced (for example) by the rapidly evolving SOTA line on the Criteo CTR prediction competition (at the time of this writing, the winner is GDCN, which is an evolved version of DCN):

Given the large economic incentives in for better recommendations, it’s guaranteed that we’ll continue to see new breakthroughs in this domain for the foreseeable future. Watch this space.
Reader question of the week
This week I’ll answer:
How do you know if an ML research paper is any good?
This is a great question. There’s a flood of ML research papers these days, and you really want to avoid investing time in a paper that’s useless. So here are a few criteria to watch out for:
Is it launched in production? This is perhaps the most important indicator of them all. Everyone can invent new algorithms and find good performance on some benchmark dataset just by tweaking the parameters enough. However, launching an algorithm is the best proof you can get that it actually works.
What’s the problem? It should be clear from the abstract what the problem is that the paper tries to solve. It’s ok if it takes a while to comprehend the solution, but the problem should be clear right away. If it isn’t, there’s a good chance the paper may be useless.
Who’s the author? Usually, I have better luck with papers coming directly from tech companies (which run ML systems in production!) than papers written by academics (although there are notable exceptions, such as NCF or AutoInt, which came from universities!) Nevertheless, there’s also “prestige bias”: just because a paper comes from Google, this doesn’t automatically mean that the idea will work for your particular application.
Is it well-cited? Having no citations is a red flag. Check out the paper on Connected Papers (see my example in last week’s issue) to figure out how it relates to the big papers in its research domain. When starting to dig into an entirely new domain, it’s usually better to start with the big nodes in the graph of papers, that is, the papers with the most citations.
Thank you for supporting Machine Learning Frontiers! If you like this newsletter, please make sure to subscribe. No spam, just the next (weekly) issue directly into your inbox. Also, I’d appreciate if you could help spread the word using the “Share” button below.
Until next week!