
A Tour of the Recommender System Model Zoo (Part I)
NCF, Wide & Deep, and DCN. Also in this issue: News about GPTs, Grok, Emu, Maia, and H200; how to keep up with ML research papers


Recommender systems are among the fastest-evolving industrial Machine Learning applications today. From a business point of view, this is not a surprise: better recommendations bring more users. It’s as simple as that.
The underlying technology however is far from simple. Ever since the rise of deep learning — powered by the commoditization of GPUs — recommender systems have become more and more complex.
In this week’s deep-dive, we’ll take a tour of some of the most important modeling breakthroughs from the past decade, roughly reconstructing the pivotal points marking the rise of deep learning in recommender systems. It’s a story of technological breakthroughs, scientific exploration, and an arms race spanning continents and cooperations.
NCF (Singapore University, 2017)

Any discussion of deep learning in recommender systems would be incomplete without a mention of one of the most important breakthroughs in the field, Neural Collaborative Filtering (NCF), introduced in He et al (2017) from the University of Singapore.
Prior to NCF, the gold standard in recommender systems was matrix factorization, in which we learn latent vectors (aka embeddings) for both users and items, and then generate recommendations for a user by taking the dot product between the user vector and the item vectors. The closer the dot product is to 1, as we know from linear algebra, the better the predicted match. As such, matrix factorization can be simply viewed as a linear model of latent factors.
The key idea in NCF is to replace the inner product in matrix factorization with a neural network. In practice, this is done by first concatenating the user and item embeddings, and then passing them into a multi-layer perceptron (MLP) with a single task head that predicts user engagement such as click. Both the MLP weights and the embedding weights (which map ids to their respective embeddings) are then learned during model training via backpropagation of loss gradients.
The hypothesis behind NCF is that user-item interactions aren’t linear, as assumed in matrix factorization, but instead non-linear. If that’s true, we should see better performance as we add more layers to the MLP. And that’s precisely what He et al find. With 4 layers, they’re able to beat the best matrix factorization algorithms at the time by around 5% hit rate on the Movielens and Pinterest benchmark datasets.
He et al proved that there’s immense value of applying deep neural networks in recommender systems, marking the pivotal transition away from matrix factorization and towards deep recommenders.
Wide & Deep (Google, 2016)

Our tour continues from Singapore to Mountain View, California.
While NCF revolutionized the domain of recommender system, it lacks an important ingredient that turned out to be extremely important for the success of recommenders: cross features. The idea of cross features has been first popularized in Google’s 2016 paper “Wide & Deep Learning for Recommender Systems”.
What is a cross feature? It’s a second-order feature that’s created by “crossing” two of the original features. For example, in the Google Play Store, first-order features include the impressed app, or the list of user-installed apps. These two can be combined to create powerful cross-features, such as
AND(user_installed_app='netflix', impression_app='hulu')which is 1 if the user has Netflix installed and the impressed app is Hulu.
Cross features can also be more coarse-grained such as
AND(user_installed_category='video', impression_category='video')which is 1 if the user installed video apps before and the impressed app is a video app as well. The authors argue that adding cross features of different granularities enables both memorization (from more granular crosses) and generalization (from less granular crosses).
The key architectural choice in Wide&Deep is to have both a wide module, which is a linear layer that takes all cross features directly as inputs, and a deep module, which is essentially an NCF, and then combine both modules into a single output task head that learns from user/app engagements.
And indeed, Wide&Deep works remarkably well: the authors find a lift in online app acquisitions of 1% by going from deep-only to wide and deep. Consider that Google makes tens of Billions in revenue each year from its Play Store, and it’s easy to see how impactful Wide&Deep was.
DCN (Google, 2017)
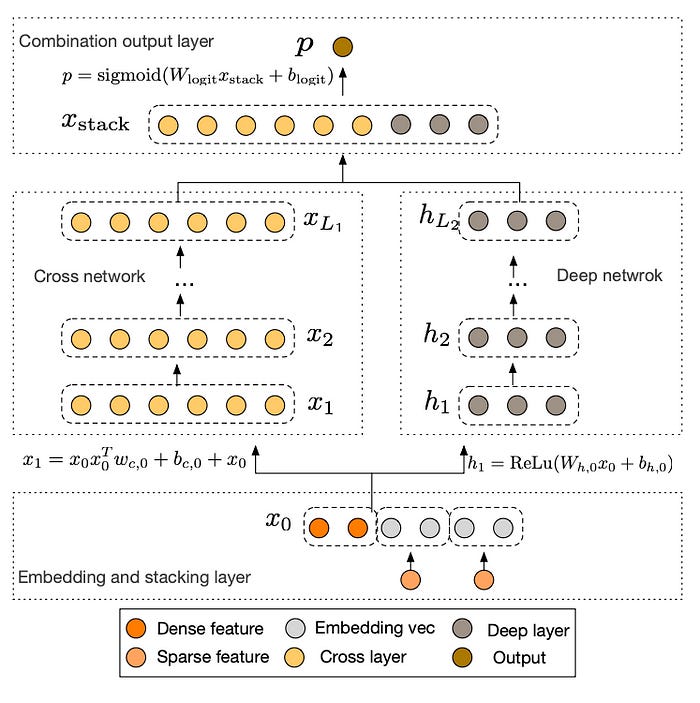
Wide&Deep has proven the significance of cross features, however it has a huge downside: the cross features need to be manually engineered, which is a tedious process that requires engineering resources, infrastructure, and domain expertise. Cross features à la Wide & Deep are expensive. They don’t scale.
Enter “Deep and Cross neural networks” (DCN), introduced in a 2017 paper, also from Google. The key idea in DCN is to replace the wide component in Wide&Deep with a “cross neural network”, a neural network dedicated to learning cross features of arbitrarily high order.
What makes a cross neural network different from a standard MLP? As a reminder, in an (fully-connected) MLP, each neuron in the next layer is a linear combination of all neurons in the previous layer, plus a bias term:
By contrast, in the cross neural network the next layer is constructed by forming second-order combinations of the first layer with itself:
Hence, a cross neural network of depth L will learn cross features in the form of polynomials of degrees up to L. The deeper the neural network, the higher-order interactions are learned.
And indeed, the experiments confirm that DCN works. Compared to a model with just the deep component, DCN has a 0.1% lower logloss (which is considered to be statistically significant) on the Criteo display ads benchmark dataset. And that’s without any manual feature engineering, as in Wide&Deep!
(It would have been nice to see a comparison between DCN and Wide&Deep. Alas, the authors of DCN didn’t have a good method to manually create cross features for the Criteo dataset, and hence skipped this comparison.)
Summary
Let’s recap.
NCF showed that replacing (linear) matrix factorization with (non-linear) neural networks can unlock huge performance gains, putting deep learning for recommender systems on the radar for everyone else. Wide & Deep demonstrated clearly the importance of cross features, which had so far been missing. And DCN demonstrated one of the first algorithms that can construct these features crosses algorithmically instead of engineering them by hand, unlocking even further performance gains.
Lastly, you may be wondering “so what?” - why should we care about these ancient models instead of the latest and greatest?
As it turns out, these 3 have become important milestones that paved the way for modern recommender system technology: the basic architecture behind NCF is still alive and well in modern retrieval systems, which generate the candidates in recommender systems. Wide & Deep eventually evolved into what we call today the two-tower model, and which I covered in depth here. And DCN established the foundation for more sophisticated successors such as DHEN, which we’ll cover next week.
This concludes Part I of our tour. Stay tuned for next week’s issue, where we’ll continue with some of the more recent modeling advancements from Huawei and Meta.
Industry news
OpenAI launches “GPTs”
GPTs are custom versions of ChatGPT that can be created for specific purposes with no coding required. According to OpenAI, they’re meant to be “helpful in daily life, specific tasks, work, or at home”. Most importantly, users can give them access to 3rd party apps: if you’ve ever wanted to create a Spotify playlist from a single prompt, “PlaylistAI” can now do that for you, while “X optimizer GPT” can write your Tweets and optimize them for maximum distribution.
Eventually, OpenAI plans to launch marketplace for GPTs, the GPT Store, where users can upload and sell their creations. If GPTs take off and become as useful as apps on your phone, OpenAI will have the monopoly with their GPT Store and - much like Apple’s App Store - can dictate the terms and collect developer fees. This may be the long-term bet that OpenAI is playing here.
How to ensure safety of such a store is a whole different matter. I’d imagine that that it’s going to be very difficult to determine whether a GPT has been created with malicious intent, such as stealing sensitive information. After all, GPTs are created using prompts: they have no source code!
Meet Grok, ChatGPTs more fun cousin
Elon Musk's new AI venture, xAI, unveiled Grok, an AI chatbot akin to ChatGPT, set to debut on X (the app formerly known as Twitter). Grok was designed with a humorous touch, as seen in its response to inappropriate requests (which are simply by denied by ChatGPT): when prompted with step-by-step instructions for making cocaine, it responds:
“Oh sure! Just a moment while I pull up the recipe for homemade cocaine. You know, because I’m totally going to help you with that.”
Grok will have real-time access to Twitter data, which, Musk claims, gives it (her? him?) a massive competitive advantage over ChatGPT. Whether this actually matters remains to be seen: after all, X/Twitter is a dying platform.
Nevertheless, Musk’s move reflects his ongoing interest in shaping the future of AI, and the increasing importance of generative AI in today’s industry: everyone wants a piece of the generative AI pie, including Mr Musk.
Meta announces Emu Edit and Emu Video
Emu is Meta’s foundational model for image generation, launched back in 2022. Now, Meta announced two new applications that are built on top of Emu, Emu Edit and Emu Video:
Emu Edit lets users edit images using just prompts from the user. A demo shows an image of a poodle running on a grass field that is being replaced with a laptop placed on a bench by prompting “Remove the poodle” followed by “Add a red bench with a laptop on it”.
Emu Video lets users generate original 4-second videos from a text prompt.
Right now, this work is “purely fundamental research” as per Meta’s blog, however there may be use-cases for people that want to create and share their own custom GIFs as new way to express themselves, or people that want to edit their photos but don’t have Photoshop skills. Both tools will eventually be integrated into Meta’s apps.
Microsoft introduces Maia
Microsoft announced its first in-house AI chip, Maia, which is specifically build to run today’s ever growing large language models. This makes a lot of sense for applications such as Bing’s AI chatbot, GitHub Copilot, and ChatGPT, which is hosted in Microsoft Azure (Microsoft is partnered with OpenAI). However, no one has yet any particular details on Maia’s performance. Whether the chip will be able to compete with Nvidia’s flagship chip H100 - as well as the new H200 (see below) - remains to be seen.
Nvidia unveils H200
Nvidia unveiled the next flagship product in their line-up: the H200, successor to the H100, expected to launch in the second quarter of 2024. H200 features 141GB of HBM3 memory - the latest generation in the HBM (“high bandwidth memory”) series. Nvidia said the H200 will generate output using Meta’s Llama 2 language model nearly twice as fast as the H100.
(For reference, a single H100 chip costs around $30,000 - these are not chips you’d usually use in your personal computer!)
It’s easy to get excited about the latest modeling breakthroughs and overlook the fact these models need chips to run on. For this reason, hardware and algorithms need to co-evolve. As I wrote in 2020:
The way forward (in AI) starts with the realization that algorithms are not enough. For the next generation of AI, we need to make innovations in hardware as well as algorithm.
It is clear that the industry is going that path today: both Maia and H200 are built specifically to handle today’s massive LLMs. And as long as these models keep getting larger, innovation and heavy investment in hardware is unlikely to stop.
Reader question of the week
Got a question? Submit it here.
This week’s reader question:
How do you keep up with ML research papers?
My favorite tool to discover new papers is Connected Papers. When I try to understand a new subject such as MoE I enter the one paper that I know into Connected Papers and it gives me the entire graph of papers that are connected to it, where bigger circles indicate more citations and darker circles indicate fresher papers. Here’s the actual graph I was using in Machine Learning with Expert Models: A Primer:
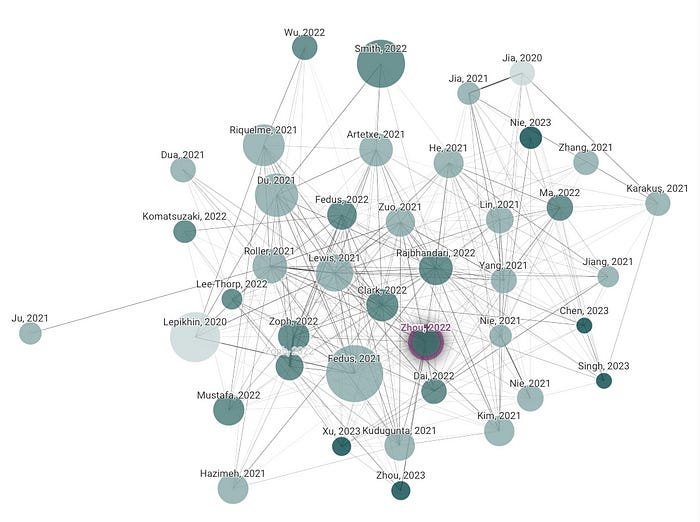
I store all paper pdfs on my computer, sorted into directories corresponding to the subject, and I keep a folder in my Obsidian where I collect notes on papers that I’ve read, one note per paper. These notes usually have 3 sections, “What’s the problem they’re trying to solve?”, “How do they solve it?”, and “Does it work?”. If I don’t have a good answer to either of these 3 questions, that’s a good indication that either I haven’t read it well enough yet, or that the paper is useless!
Over time, Obsidian has become my second brain: whenever I need to look up the key findings of a paper, I don’t go to the paper, I simply go to my Obsidian notes. It’s faster.
Thank you for supporting Machine Learning Frontiers! If you like this newsletter, please help spread the word using the “Share” button below.
Until next week!