
Pushing the Limits of the Two-Tower Model
The MixEM model, the Dot-Product model, and cross-positional attention


Welcome to this week’s issue of Machine Learning Frontiers! Here are recent issues you may have missed:
This week, we’ll revisit the two-tower model, a common architectural choice for debiasing recommender systems, which I covered in depth in my previous post here.
We’ll take a closer look at two assumptions behind this architecture, in particular:
the factorization assumption, i.e. the hypothesis that we can simply multiply the probabilities computed by the two towers (or add their logits), and
the positional independence assumption, i.e. the hypothesis that the only variable that determines position bias is the position of the item itself, and not the context in which it is impressed.
We’ll see where both of these assumptions break, and how to go beyond these limitations with newer algorithms such as the MixEM model, the Dot Product model, and XPA.
Let’s start with a very brief reminder.
Two-tower models: the story so far
The primary learning objective for the ranking models in recommender systems is relevance: we want the model to predict the best possible piece of content given the context. Here, context simply means everything that we've learned about the user, for example from their previous engagement or search histories, depending on the application.
However, ranking models usually exhibit certain observation biases, that is, the tendency for users to engage more or less with an impression depending on how it was presented to them. The most prominent observation bias is position bias - the tendency of users to engage more with items that are shown first.
The key idea in two-tower models is to train two “towers”, that is, neural networks, in parallel, the main tower for learning relevance, and a second, shallow, tower for learning all sorts of observation biases in the data. The logits from the two towers can then be added to compute the final predictions, as done in YouTube’s “Watch Next” paper:
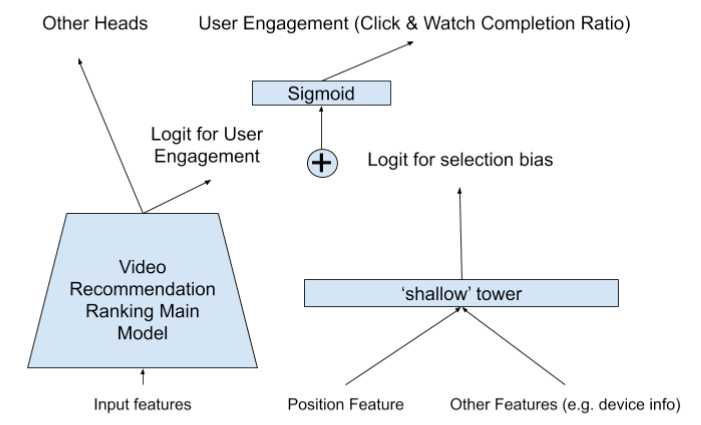
The underlying hypothesis is that by having a dedicated tower for biases, the main tower can focus on the main learning objective, that is, relevance. Indeed, empirically two-tower models have been shown to bring substantial modeling improvements:
Huawei’s PAL improved click-through rates in the Huawei App Store by 25%,
YouTube’s two-tower additive model improved engagement rates by 0.24%, and
AirBnb’s two-tower model improved booking rates by 0.7% .
In short, two-tower models work by decomposing the learning objective into relevance and bias, and have shown to bring substantial improvements in ranking models across the industry.
The factorization assumption
Two-tower models rely on the factorization assumption, that is, the hypothesis that we can factorize click predictions as
p(click|x,position) = p(click|seen,x) x p(seen|position, ...),that is, the product of click probability given that the item was observed by the user (the first factor) times the probability that the item was observed given the position (and other observational features). TouTube re-formulated this as a sum of logits instead of a product of probabilities, which is roughly equivalent:
logit(click|x,position) = logit(click|seen,x) + logit(seen|position, ...)However, it’s easy to see where this factorization assumption breaks. For example, consider a scenario where the training data consists of two different types of users, Type 1 and Type 2:
Type 1 users always click on the first item they’re shown. They’re impatient and seek immediate rewards.
Type 2 users always scroll through the items they’re being shown until they find exactly what they’re looking for. They’re patient and choosy.
Keep reading with a 7-day free trial
Subscribe to Machine Learning Frontiers to keep reading this post and get 7 days of free access to the full post archives.