
Machine Learning Frontiers in 2023: The Story So Far
Neural recommenders, two-tower architecture, Mixtures of Experts, and multi-task learners


Machine Leaning Frontiers launched in October 2023 with 0 subscribers, and - at the time of this writing - is read by 433 subscribers from 46 countries around the world. When I started this Newsletter, I wouldn’t have predicted that its growth would be this rapid. Thank you to all of my subscribers around the globe!
This week, I thought it may be useful to take a step back to review what we’ve learned so far in our journey. We’ll cover:
The blueprint of modern neural recommender system architectures,
The two-tower architecture: how we debias modern ranking models,
Mixtures of Experts: how a decades-old invention powers outrageously large neural networks today, and
Multi-task learning: design considerations and challenges when training models on multiple tasks at the same time.
1. The blueprint of neural recommenders
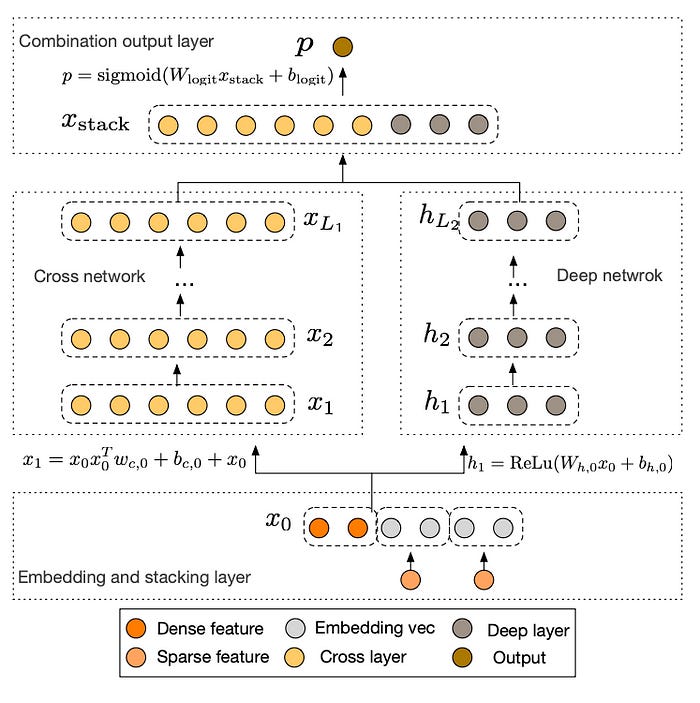
If you start to learn about recommender systems today, you’ll most likely find references to collaborative filtering with matrix factorization, which has been the gold standard in the domain probably until the mid-2010s or so. Then deep learning - powered by the commoditization of GPUs - came around and changed the game for everyone. Deep neural recommenders allowed for much richer, non-linear, engagement modeling, and has enabled one breakthrough after the next.
In the two-part series “A Tour of the Recommender System Model Zoo” (Part I, Part II) we reviewed some of the architectural design choices and modeling breakthroughs behind modern, neural recommender systems:
NCF, which stands for "neural collaborative filtering" (He et al, 2017) was among the first papers that replaced the (then standard) linear matrix factorization algorithms with a neural network, paving the way for deep learning in recommender systems.
Wide & Deep (Chen et al, 2016) demonstrated the importance of cross features, that is, second-order features that are created by crossing two of the original features. The Wide & Deep architecture combines a wide and shallow module for cross features with a deep module much like NCF.
DCN, which stands for "deep and cross neural network" (Wang et al, 2017) was among the first architectures that replaced manual engineering of cross features with an algorithmic approach that automatically creates all possible feature crosses up to any arbitrary order.
DeepFM (Guo et al, 2017) is much like DCN, however it replaces the "cross layers" in DCN with factorization machines, that is, dot products.
AutoInt (Song et al, 2018) introduced multi-head self attention: instead of simply generating all possible feature interactions in a brute-force way (which can make the model overfit to noisy feature crosses), we use attention to let the model learn which feature interactions matter the most.
DLRM (Naumov et al, 2019) dropped the deep module, and instead used just an interaction layer that computes dot products (much like DeepFM's FM part), followed by an MLP, showing that interactions are really all you need.
DHEN (Zhang et al, 2022) goes a step further than DLRM by replacing the dot product with a hierarchy of feature interactions that include the dot product, convolution, AutoInt-like self-attention, and DCN-like crossing.
And this is just the tip of the iceberg. Neural recommenders are still rapidly evolving, and I expect to see new breakthroughs in this domain in the coming years.
2. The two-tower architecture
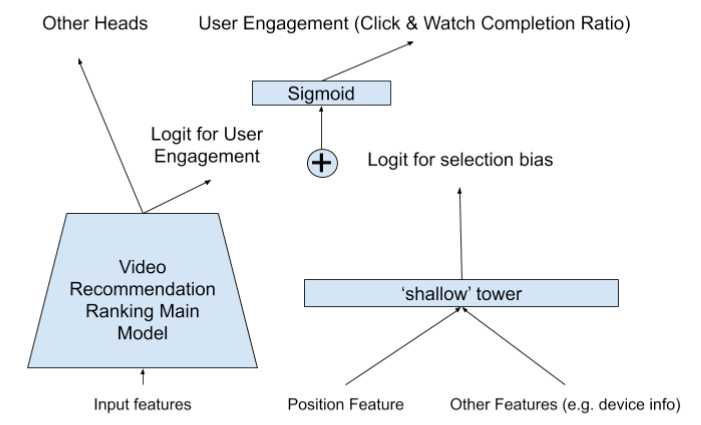
No matter the particular architecture that’s chosen, all modern recommender systems have a single thing in common: they suffer from various biases, which are really shortcuts between certain observations such as the item’s position in the user’s feed and the target variable such as “click”.
If bias becomes a confounder for relevance, this can lead to sub-par recommendations, and one of the important research threads in recommender systems is therefore how to debias them.
In “The Rise of Two-Tower Models in Recommender Systems” we’ve learned about a very commonly used architecture used to debias modern recommender systems: the two-tower model, where we let the main tower learn relevance, and add a second, shallow, tower for learning all sorts of observation biases such as position bias.
Mathematically, this boils down to factorizing the learning objective as
p(click|x, position, ...) = p(click|seen, x) x p(seen|position, ...)which YouTube re-formulated as a sum of logits instead of a product of probabilities:
logit(click|x, position, ...) = logit(click|seen, x) + logit(seen|position, ...)Empirically, two-tower models have been shown to bring substantial gains in modeling performance - here are just a few examples from the literature:
Huawei’s PAL improved click-through rates in the Huawei App Store by 25%,
YouTube’s two-tower additive model improved engagement rates by 0.24%,
AirBnb’s two-tower model improved booking rates by 0.7% .
Despite their success though, two-tower models aren’t without flaws. In Pushing the Limits of the Two-Tower Model, we’ve looked at two assumptions behind two-tower models and where they fail: the factorization assumption and the positional independence assumption.
The factorization assumption is the assumption that we can simply add the logits from the two towers (or multiply their probabilities), as shown in the equation above. This assumption breaks as soon as we consider that there are different user cohorts in the data, each exhibiting different types and degrees of observational biases: some users may always click on the first thing they see, while others may always swipe on until they find exactly what they’re looking for. Google’s MixEM model, which leverages a mixture of bias towers instead of a single one, is one way to go beyond this limitation.
The positional independence assumption is the assumption that observational bias at position p only depends on the position itself, and not on the items that are shown at the neighboring positions, p-1, p+1, and so on - this makes modeling simpler, but it’s an assumption that doesn’t hold in the real world. XPA, short for cross-positional-attention, is an algorithm that goes beyond this limitation. The key idea is to pass not just the position of the candidate item into the bias tower, but also the positions and features of the neighboring items, represented as a single embedding. In order to compute that single embedding for the neighbors, we can leverage an attention function, which in XPA is chosen to be a scaled softmax. XPA improved CTRs in the Chrome Web Store by +6.2%.
3. Mixtures of Experts

Mixtures of Experts (MoE) have become a key component in modern LLMs, as we’ve seen in breakthroughs such as Google’s Switch Transformer, OpenAI’s GPT-4, or Mistral AI’s Mixtral. However, MoE itself is nothing new - it was invented more than 3 decades ago in the 1991 paper “Adaptive Mixtures of Local Experts” co-authored by none other than the godfather of AI, Geoffrey Hinton.
In Machine Learning with Expert Models: A Primer we revisited the blueprint of MoE models: at a high level, we write a learning objective y as a weighted sum of expert outputs, where the weights are determined by a gating network
G = softmax(Wx)where W is a learnable matrix. The learning objective in MoE models is therefore two-fold: experts learn to specialize in a certain domain of the data, while the gate learns which expert to use for which kind of inputs.
We also learned about hard routing, which is the idea of sending the data just to the single, highest-weighted. Most importantly, hard routing, allows us (in theory) to scale up neural networks with ~O(1) computational complexity because we can keep adding more experts while keeping the total amount of compute constant.
In Towards Understanding the Mixtures of Experts Model, we explored the research question of what exactly happens under the hood when we train MoE models. Taking a step back, it’s absolutely not clear a priori that MoE should work - in principle, the gate could simply end up sending all training example to a single expert. Or all experts could end up learning the same patterns, in which case MoE would collapse into a simple sum pooling operation.
Instead, what happens during MoE training is that the gate learns to cluster the data (much like any other clustering algorithm such as k-means), and to assign each cluster to one expert, while the experts learn to specialize on their respective clusters. Research into MoE training (Chen et al 2022) shows that this expert allocation is random initially, and that small fluctuations in the initial allocation seed the eventual expert specialization that happens later on during training.
4. Multi-task learning

Multi-task learning is the backbone behind many of today’s ML applications. Being able to train a single model on multiple tasks not only saves cost, it can also make the performance on the main task better. In Multi-Task Learning in Recommender Systems: Challenges and Recent Breakthroughs we revisited the fundamental design principles and research questions behind multi-task learners.
Not all tasks can be learned well together: instead, tasks can help each other, creating positive transfer, or conflict with each other, creating negative transfer. Figuring out which tasks to learn together is an NP-hard problem and still an active research domain (e.g., Standley et al 2019).
The simplest neural architecture in multi-task learning is the “shared bottom” architecture, in which we combine a bottom module that’s shared across all task with task-specific modules at the top. This architectural choice allows the model to learn both shared patterns as well as task-specific pattern, however it assumes that the neural capacity per task is equal across all tasks and known ahead of time, both assumptions that may not hold in the real world.
MMoE (multi-gate mixture of experts) is a way to allocate modeling capacity in a multi-task model dynamically instead of statically. The key idea is to introduce N gates, one for each task, and let these gates allocate experts that replace the task-specific modules in the shared bottom architecture. Empirically, MMoE has been shown to mitigate negative transfer and improve overall model performance compared to both single-task learning as well as shared-bottom models.
In Multi-Task Optimization in Neural Networks: Theory and Practice, we considered the research question of how we optimize neural networks on multiple tasks at the same time. Mathematically, the answer is scalarization: we minimize the weighted sum of the task-specific losses, and then simply sweep over all possible weight settings and choose a set of weights that most aligns with what we want to achieve.
However, sweeping over the weights may become prohibitively expensive when the model size, the number of tasks, and the amount of data all become large. Instead of tuning the weights, here are two tricks that have been shown to work well in practical applications:
In Learnable Loss Weights (Kendall et al 2018), instead of tuning the loss weights by hand, we adjust them heuristically based on the model uncertainty. If the model is wrong and certain for a task we apply a larger weight to that task's loss compared to when the model is wrong and uncertain. On an object detection problem, the authors were able to get 13% better IoU with learnable loss weights compared to a baseline of fixed loss weights.
In Gradient Surgery (Yu et al 2020), we manipulate the gradients of competing tasks directly such as to minimize negative transfer. In particular, we project the gradient from one task onto the normal plane of the other, alternating the gradient that’s being projected at each training step. The authors report a 30% absolute improvement on a multi-task reinforcement learning problem when using PCGrad compared to single-task learning methods, that is, using one model per task.
What’s next…
Here are some of the upcoming topics we’ll explore in the new year:
The DCN family: DCN-V2 and GDCN. GDCN, which is a version of DCN with added information gating modules, is the current leader on the Criteo display ads benchmark dataset. How does it work? Why does it work so well?
Sparse MoE: Sparse MoE models have become the key component in modern LLMS. What are the challenges in scaling them, and how do we overcome these challenges? How to ensure load balance when there’s not guarantee about the experts or the gate behavior ahead of time?
MoE with many gates: how do multi-gated MoEs work? Why are they considered “robust” multi-task learners? How should we allocate gates to tasks?
User history modeling: how do we encode user histories in recommender systems?
Hashing: how do we represent high-cardinality, multivalent categorical features in recommender systems? How can we prevent collisions in hash space?
All this and more in 2024. Stay tuned, and happy holidays.
Machine Learning Frontiers is a one-man startup with a mission to open the black box and make modern ML algorithms accessible to anyone. If you support this mission, consider becoming a paid subscriber. (Tip: most universities and tech employers will likely let you expense it!) As a paid subscriber, you’ll also get access to the growing ML Frontiers archive.
Do you think Gradient surgery can be complementary or additive in a system that already uses LLW?
Wonderfully detailed! Congratulations on your deserved growth. Looking forward to reading your work in 2024. Happy holidays!