
The Rise of Generative Recommenders
Understanding Kuaishou's OneRec architecture - and what it means for the future of recommender systems


Traditional recommender systems follow a three-stage architecture: candidate retrieval, ranking, and a value model (VM). Each stage is optimized separately, often by different teams, and improving one doesn’t guarantee better end-to-end performance. For example, stronger candidates from retrieval may be ignored by the ranker, or better ranking scores may be underweighted in the VM. This fragmented design makes the system hard to scale and tune holistically.
Moreover, these systems don’t benefit much from model scaling. Unlike LLMs, where simply adding more Transformer blocks has been shown to improve performance, increasing the size of models like DCN or DLRM rarely yields notable gains in ranking accuracy.
Generative recommenders (GRs) aim to replace this entire stack with a single, unified model—typically a Transformer—that directly generates the next item a user is likely to engage with, much like how an LLM generates the next word in a sentence. This shift reframes recommendation as a sequence modeling problem (which is the next item in the sequence?) instead of a classification problem (how likely is the user to engage with this item?).
In this post, let’s take a look at Kuaishou’s OneRec, a GR for video recommendation, and one of the first industrial examples for a production system directly generating item ids.
Tokenization
The major challenge in GRs is the vocabulary size. A typical recommender might deal with billions of item IDs, compared to ~32K tokens in a language model like LLaMA. Simply treating item IDs as discrete tokens may not work because, unlike natural language, item IDs lack semantic repetition and structure, and many are cold-start and/or short-lived. It’s like trying to learn a language when the words are constantly changing and have no underlying structure.
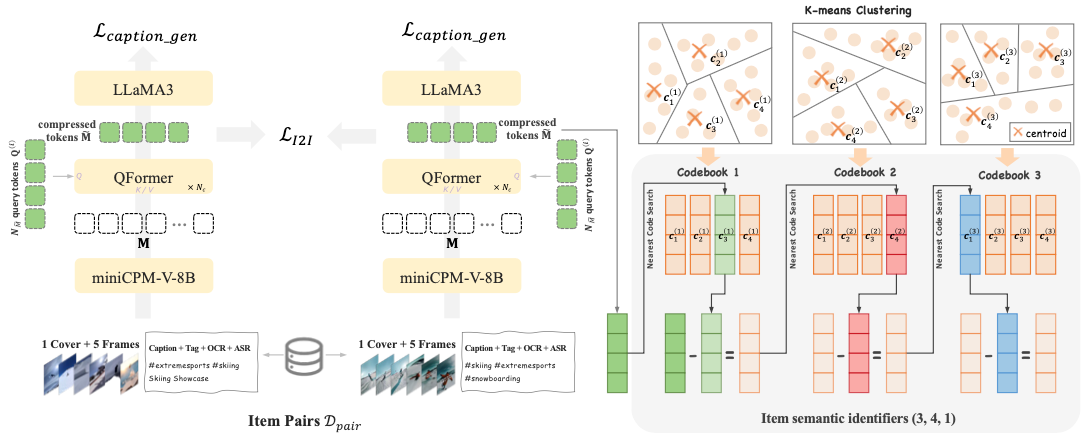
The semantic item id, introduced in Google’s TIGER paper, has thus become a critical ingredient for GRs. Here’s how OneRec generates its semantic ids:
Step 1 - Feature extraction. We begin by extracting rich, multimodal features from each video, combining both metadata and content. This includes text data from the caption, tags, ASR (speech-to-text), and OCR (extracted from frames), as well as the cover image and five randomly sampled video frames.
Step 2 - Embedding generation. These features are then fed into a miniCPM-V-8B model, an 8B-parameter, multimodal LLM designed for text, image, and video understanding. The model is trained using item-to-item contrastive loss to learn video similarity and a caption loss to mitigate hallucinations. It outputs 1280 512-dimensional token vectors per video.
Step 3 - Compression. The 1280 token vectors per video are compressed to just 4 using a QFormer (Querying Transformer).
Step 4 - Discretization. We run the resulting video embeddings through a 3-layer Residual-Quantization k-means (RQ K-means) algorithm with k=8192. This is a hierarchical clustering algorithm where each stage generates more refined clusters. This results in 3 “codebooks” which map each continuous embedding to its corresponding cluster center (for example, the item id 100592759244 may be mapped to [301,99,7011], hence its semantic id would be 301997011). Given the choice of k=8192, this results in more than 500B unique semantic ids, more than enough for a modern recommender system.
In addition to enabling next-item prediction, another benefit of the semantic id is that it also solves the cold-start problem. While traditional recommenders require user interactions on a new item to learn its relevance, semantic ids allow the model to understand the item’s relevance even before any user has engaged with it.
Model architecture and pre-training
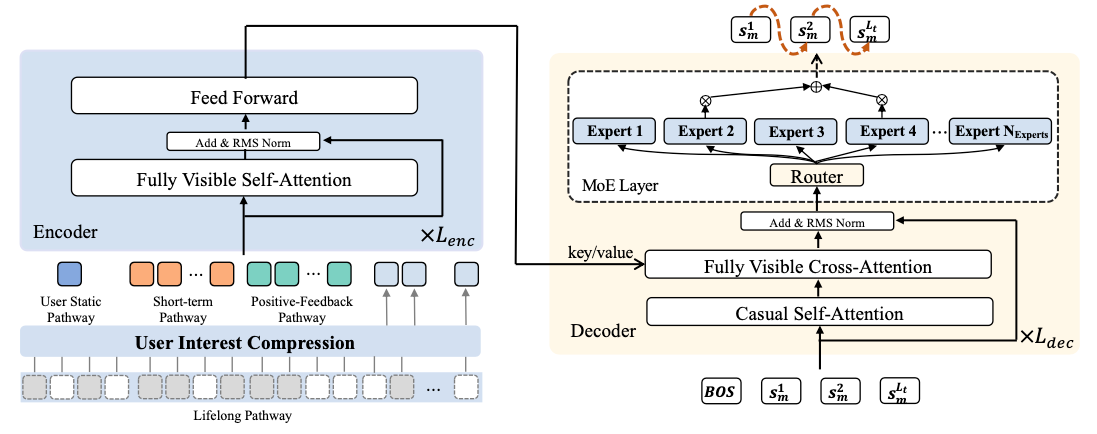
The OneRec model itself is an encoder-decoder architecture that takes as input the user history of engaged videos and outputs the 3 next tokens, which can be mapped to a video id using the codebooks. Similar to LLMs, the model is then trained on the next-token prediction task with cross-entropy loss.
The encoder consists of 4 separate sub-architectures which process different sets of input signals:
user static pathway: user id, age, gender, and any other static variables,
short-term pathway: the most recent 20 video interactions for the user,
positive-feedback pathway: the most recent 256 videos with explicit user interactions (like, follow, comment, share),
lifelong pathway: the entire user engagement history compressed using SIM (search-based interest modeling), which uses semantic topic matching against the target topic for compression.
The decoder is a variant of a sparse Transformer model with the addition of cross-attention to better capture the interactions of the different input pathways. Similar to the Switch Transformer or Mixtral of Experts, it uses hard routing in the MoE layer to save compute, but with the dynamic load balancing algorithm from DeepSeek.
The authors report that the model was “pre-trained” (trained on user action sequences with next-token prediction objective) on 90 GPU nodes, each equipped with 8 “flagship” GPUs, which I would guess to be at least NVIDIA H100’s. As usual, the devil for efficient pre-training lies in the details, requiring advanced tricks such as parameter servers for embeddings, training and model parallelism, mixed precision training, and compiler optimizations. The authors report that pre-training converges after around 100B samples.
Reinforcement learning from user feedback
If we just pre-train OneRec on the existing data, it will eventually become very good at parroting the existing production model, but not better. In the author’s words,
“This results in the model being unable to break through the ceiling of traditional recommendations.”
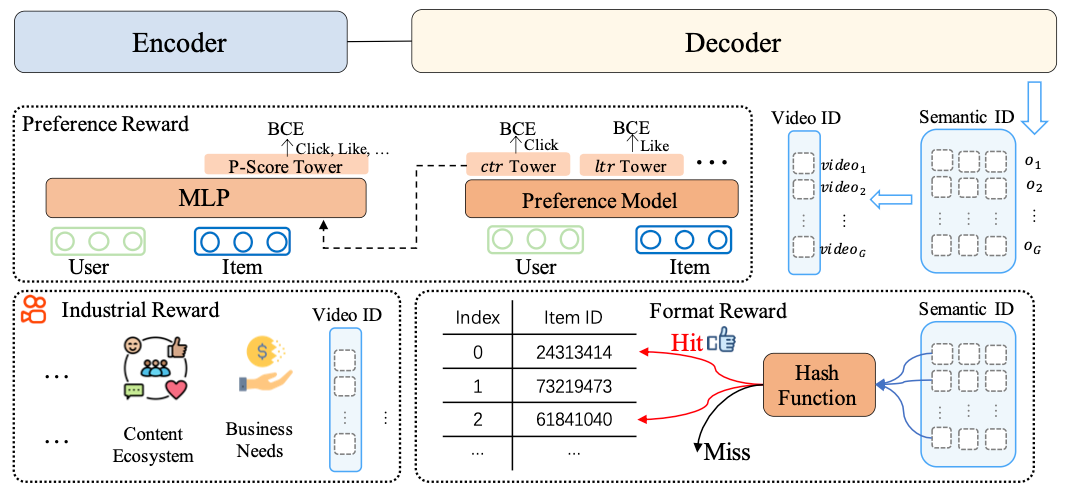
In order to break through that ceiling, the authors employ reinforcement learning with actual user feedback, similar to how RLHF (reinforcement learning with human feedback) on top of a pre-trained LLM resulted in ChatGPT. This is done using 3 rewards:
preference reward: a learned reward model trained to predict user preference by combining multiple engagement signals such as watch times, likes, comments, follows, etc, similar to a VM in the traditional recommender system.
industrial reward: constraints derived from Kuaishou’s product requirements. One example mentioned in the paper is how the industrial reward was used to constrain the ratio of viral videos in the feed.
format reward: to ensure the generated code triplets are valid semantic item IDs, i.e. those that can actually be mapped back to a real video. Think of this like the equivalent of penalizing an LLM for making up words.
Under the hood, OneRec uses ECPO (Early Clipped Policy Optimization) for optimization, which is a variant of the GRPO/PPO family of policy-gradient methods originally used in RLHF for models like ChatGPT and DeepSeek.
Results
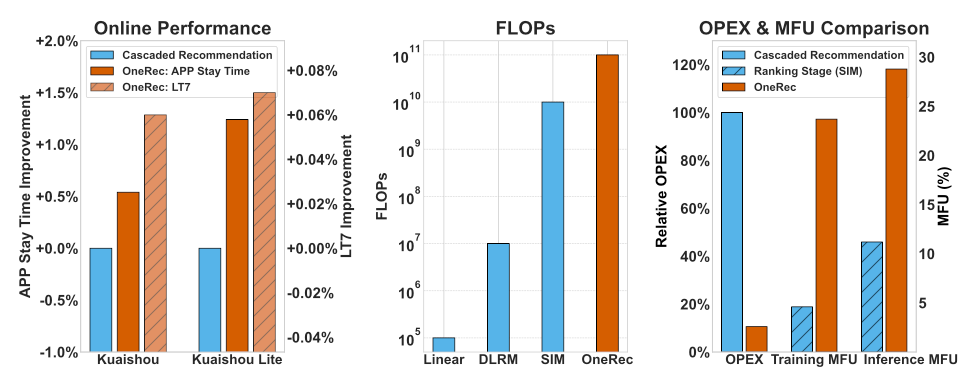
One of the major benefits of OneRec over a traditional, staged system is its better compute utilization because no data has to passed around in between stages. We can measure this efficiency gain in MFU, or “model FLOP utilization”, which measures the ratio of model FLOPs to the theoretical maximum GPU FLOPs. The authors report MFUs of 23.7% for training and 28.8% for inference, which is 5.2X and 2.6X higher, respectively, compared to a traditional recommender system, and closer, but not quite as good, as modern LLMs which can get up to 40% MFU.
In addition to improved efficiency, OneRec’s recommendations are also better as measured by App Stay Time, which improved by 0.54% in the Kuaishou app and 1.24% in Kuaishou Lite. OneRec was also rolled out to Kuaishou’s e-commerce app “Local Life Service”, where it drove +21% GMV. These are remarkable results, illustrating the potential headroom that is left on top of traditional recommender architectures.
Is this RecSys’ ChatGPT moment?
Is this the end of traditional recommender systems as we know them? The ChatGPT moment for RecSys?
It may very well be, but we will need to see how well GRs are going to be adopted, and how quickly this is possible. Even in Kuaishou’s case, OneRec has reportedly only been rolled out to 25% of queries, which could indicate either technical hurdles for a full roll-out or simply that Kuaishou is hedging their bets as the long-term impact of GRs is still unknown.
That said, Kuaishou is not the only company investing heavily in generative recommendation. There’s Netflix’s Foundation Model, Pinterest’s PinFM, Xiaohongshu’s RankGPT, Meta’s HSTU, and more. Out of these, Netflix FM and PinFM are perhaps most similar to OneRec in that they’re also generating the next item id, with the difference that OneRec predicts semantic ids while Netflix and PinFM predict item ids directly (which may be okay because their item catalogs are more stable than Kuaishou’s ephemeral short-form videos). HSTU and RankGPT on the other hand are slightly different in that they predict the next set of actions on the next item in the sequence, not the item id directly.
If this truly is RecSys’ ChatGPT moment, it is also reasonable to expect a lot of disruption in the recommendation industry over the coming years, including the job market. Say a modern tech giant employs hundreds of engineers on a traditional recommender stack including retrieval, ranking, and VM tuning. How many of those are still needed for a single GR? And which ones? What skills do they need? How much work is needed for ongoing maintenance and improvements? And how to iterate on such a massive model anyway?
These are all things that need to be figured out. Exciting (and disruptive) times are ahead. Until next time!