
The Rise of Sparse Mixtures of Experts: Switch Transformers
A deep-dive into the technology that paved the way for the largest and most capable LLMs in the industry today

 in the context of large language models. The image features an array of diverse, abstract experts represented as futuristic, glowing entities, interconnected by a complex network of digital pathways, symbolizing the flow of information and decision-making. These entities are set against a backdrop that suggests advanced technology, with subtle references to artificial intelligence and machine learning, like circuit patterns and neural network diagrams. The overall tone is high-tech and cutting-edge, emphasizing the innovative nature of Sparse MoE in AI development.")
Welcome to this week’s issue of Machine Learning Frontiers! Here are recent issues you may have missed:
Sparse Mixtures of Experts (MoE) has become a key technology in the latest generation of LLMs such as Google’s Switch Transformer, OpenAI’s GPT-4, Mistral AI’s Mixtral, and more. In a nutshell, sparse MoE is an extremely powerful technology because - in theory - it allows us to scale up capacity of any model with a computational complexity of O(1)!
However, as is often the case, the devil lies in the details, and getting sparse MoE to work correctly requires to get these details exactly right.
In this week’s post, we’ll dive into one of the pivotal contributions in the domain of sparse MoE, the Switch Transformer (Fedus et al 2022), which demonstrated for the first time the impressive scaling properties one can achieve with this technology, achieving 7X speed-up in training of a Transformer model. We’ll cover:
hard routing: the favorable scaling properties that come from executing just a single expert per token,
the Switch Transformer architecture: how MoE fits into the broader context of the Transformer architecture,
token routing dynamics: how the capacity factor is used to trade off computational efficiency against modeling accuracy, and
empirical results: the impressive scaling properties of the Switch Transformer.
Let’s get started.
Hard routing
As a reminder, the key idea in MoE is to model an output y given an input x using a linear combination of experts E(x), the weight of each is being controlled by a gate G(x),
where the gate is simply a softmax of the inputs x multiplied with a learnable weight matrix W:
When training MoE models, the learning objective is therefore two-fold:
the experts will learn to process the input they’re given into the best possible output (i.e., a prediction), and
the gate will learn to assign the right training examples to the right experts by learning the matrix W.
This original formulation of MoE, which traces back more than 3 decades ago to original work from Geoffrey Hinton in the 90s, has today become known as soft routing. “Soft” because even though different experts may end up with vastly different weights (some of them barely noticeable), we still combine the output from all experts in the final results, no matter how small their contribution.
In hard routing, by contrast, we run the forward pass over just the single most suitable expert, as determined by the gate, that is, we approximate
where I the index i that maximizes G.
The motivation behind this approach is to trade off a little bit of modeling accuracy against a large amount of savings in computational cost: if an expert had a weight of 0.01, say, is it really worth running a forward pass over that expert?
By the way, hard routing is really a special case of top-k routing, originally proposed in Shazeer et al (2017), with k=1. While Shazeer et al hypothesized that using k=1 may not work well in practice because this would drastically limit the gradients flowing back through the experts, the Switch Transformer proved otherwise.
(Note that the terms “gate” and “router” are often used interchangeably - in the context of sparse MoE, they really mean the same thing.)
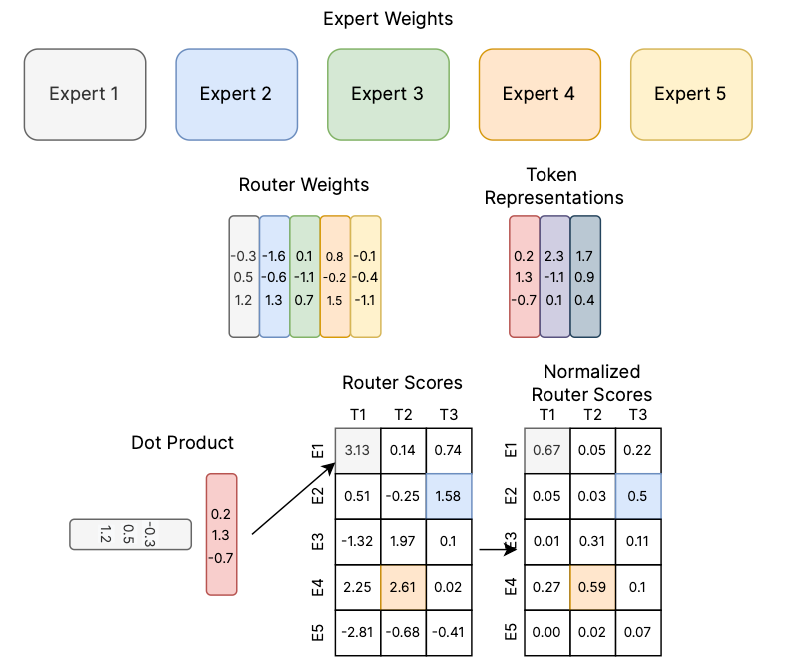
The Switch Transformer architecture
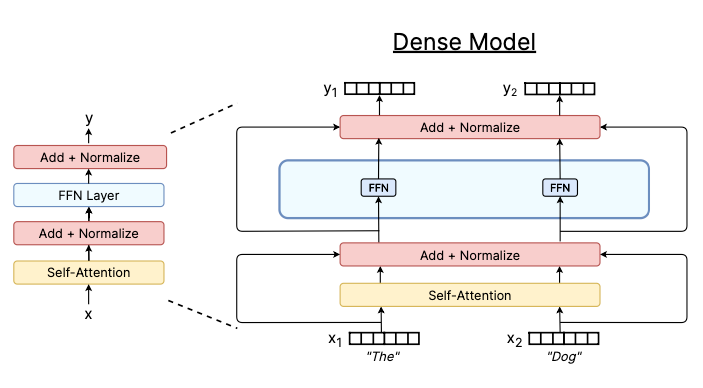
In a regular (dense) Transformer block, we stack a feed-forward neural network (FFN) layer on top of a Self-Attention layer, with residual connections in between them. At a high level, the self-attention layer selects what inputs the model pays attention to, and the FFN layer processes that input and passes the output into the next block, and so on. BERT-Large, for example, is a Transformer model that stack 24 of these Transformer blocks.
Here’s a visualization of this dense Transformer block:
In the Switch Transformer, we replace the single FFN module with multiple FFN “experts”, and let a hard router assign tokens to experts, as such:

Most importantly, these two architectures have identical computational complexity, but the latter model has actually 4x the modeling capacity (i.e., number of neurons), compared to the former! This is possible only thanks to hard routing with sparse MoE: while we have now 4 FFNs instead of one, only one of them will be active for any given token.
Token routing dynamics and capacity factor
So far we have only considered how the router distributes tokens in between experts, but not where exactly these experts live. In practice, we typically distribute experts across machines, a form of model parallelism that’s also known as expert parallelism.
Expert parallelism has an important physical limitation: we can’t route more tokens to an expert than the memory on its machine’s memory allows!

In this context, we define expert capacity as
capacity = f x T/Ewhere T is the number of tokens, E is the total number of experts, and f is a free hyperparameter which we call the capacity factor. (If we use top-k routing with k>1, then we’d also add a factor of k to the right hand side of the equation - however, since here we consider the Switch Transformer which uses hard routing, we’ll use k=1.)
For example, with T=6, E=3, and f=1, we’d allow the router to send up to 2 tokens to each expert, as shown in the left panel of the figure above. If we send more, we’ll need to drop the extra tokens, and if we send less, we’ll need to pad the input to the expert such as to ensure consistency - after all, the computational graphs that can be run on GPUs have to be static, they can’t be dynamic.
The capacity factor f thus introduces a trade-off: too large, and we waste compute resources by excessive padding (these are the white rectangles in the figure above). Too small, and we sacrifice model performance due to token dropping (indicated by the red arrows in the figure above).
In the Switch Transformer paper, the authors find the better performance with lower capacity factors, for example reducing f from 2.0 to 1.0 improved log perplexity from -1.554 to -1.561 after 100k steps. This indicates that the penalty we incur by token dropping is not as bad as that from under-utilizing compute resources. Or put more simply: it’s better to optimize for resource utilization, even at the cost of token dropping.
Scaling properties of the Switch Transformer
Most importantly, Switch Transformers can be scaled up with approximately constant computational complexity simply by increasing the number of experts. This is because more experts don’t result in more expert forward passes - thanks to hard routing - and the additional computation that needs to be done by the gate when adding more experts is negligible compared to the entire model architecture, in particular compared to the computationally heavy Transformer blocks.
The figure below shows that by replacing the single FFN module with 128 sparse experts, the authors were able to get to the same performance as the T5 language model, but 7x faster! All models here were trained on the same machines, 32 TPUv3 cores, with equal FLOPs per training example.
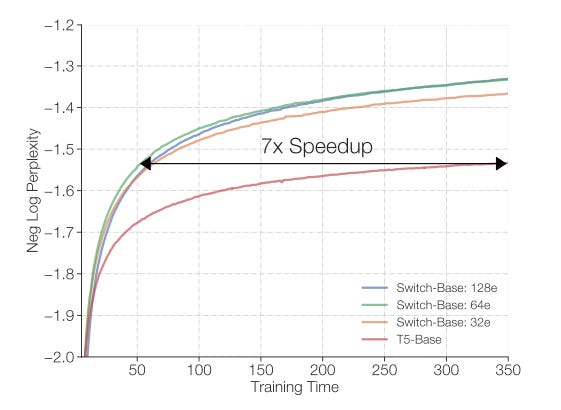
At first glance, this looks like magic. How is it possible to be that much faster with the same amount of FLOPs? It’s the equivalent of a car getting to a destination 7x faster while driving at the same speed!
The answer is, once again, that Switch Transformer leverages sparsity, in particular sparse MoE. While we’ve added modeling capacity in the form of more experts, we’ve kept the FLOPs constant because of hard routing, that is, we don’t actually execute all of the experts in each training iteration, but only the most suitable expert per token.
Take-away
Let’s recap:
Sparse MoE is a groundbreaking technology because it allows us to scale modeling capacity with a computational complexity of ~O(1), and has enabled breakthroughs such as Google’s Switch Transformer, OpenAI’s GPT-4, Mistral AI’s Mixtral, and more.
Hard routing means that we run the forward pass over just the single, most suitable expert instead of all the experts, which saves FLOPs.
The Switch Transformer replaces the FFN layers in the T5 Transformer with sparse MoE layers that use hard routing.
The capacity factor determines how many tokens are being allowed per expert, and is a lever for trading off between token dropping and machine utilization. Experiments show that maximizing machine utilization, even at the expense of token dropping, is the right thing to optimize for.
Thanks to its favorable scaling properties, the Switch Transformer enabled a speed-up of 7X in training speed compared to the T5 (dense) Transformer model.
While the Switch Transformer has been a breakthrough in LLMs, I believe that we're just starting to see its full impact on the industry. The powerful scaling properties enabled by sparse MoEs have the potential to bring drastic modeling improvements in applications across domains, not just LLMs. It’s an exciting time in ML!
Machine Learning Frontiers is a one-man startup with a mission to open the black box and make modern ML algorithms accessible to anyone. If you’d like to support this mission, consider becoming a paid subscriber.