
The Rise of Deep and Cross Networks in Recommender Systems
DCN is the leading architectural family on click prediction leaderboards - here's what's under the hood


The Deep and Cross neural network (DCN), introduced in Wang et al 2017, was an important breakthrough in recommender system modeling, demonstrating the significant performance gains from replacing the manual engineering of cross features in Wide&Deep-like architectures with an algorithmic approach that simply computes all possible feature crosses in a brute-force way.
It’s an architectural choice that intuitively makes a lot of sense and empirically has been shown to be very powerful. Even today, DCN-like algorithms still lead click prediction leaderboards such as Criteo.
Let’s take a look at what’s under the hood of DCN and its successors DCN-V2, DCN-Mix, and GDCN.
Cross features - a lightning primer
Cross features are second-order feature that are created by “crossing” two of the original features, first popularized in Google’s 2016 paper “Wide & Deep Learning for Recommender Systems”. For example, in Google Play Store recommendations, a cross feature could be
AND(installed_app='netflix', candidate_app='hulu')which is 1 if the user has Netflix installed and the candidate app to be ranked is Hulu. Cross features can also be more coarse-grained such as
AND(installed_app='video', candidate_app='video')which is 1 if the user installed video apps before and the candidate app is a video app as well. The authors of Wide&Deep argue that adding cross features of different granularities enables both memorization (from more fine-grained crosses) and generalization (from more coarse-grained crosses).

The Wide&Deep architecture combines a deep neural network architecture for processing features directly with a wide and shallow tower for processing hand-engineered cross features. In the paper, the authors estimate that adding this wide tower enables +1% in online app conversions, compared to a deep-only neural network.
Consider that Google makes tens of Billions in revenue each year from its Play Store, and it’s easy to see what an impactful innovation Wide&Deep was.
DCN - brute-force cross features
Wide&Deep relies on manual engineering of cross features, which obviously does not scale well. The key idea in DCN is to instead generate all possible feature crosses algorithmically using a “cross neural network” architecture.
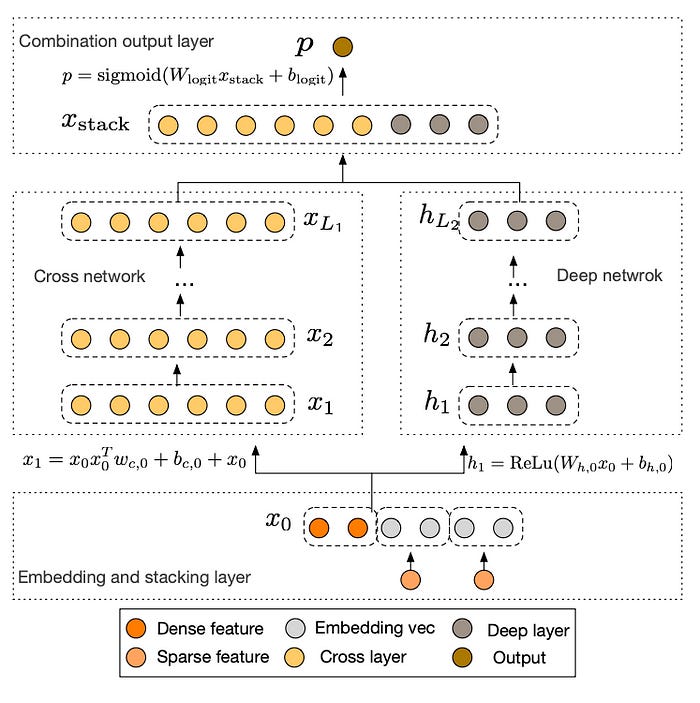
The cross network is simply a stack of cross layers, where a single cross layer performs the following computation:
where
l is the index of the cross layer,
x is the feature vector, and the index T refers to its transpose,
w and b are learnable parameters, i.e. weights and biases inside the cross layer,
x_0 is the original feature vector.
The intuition is that in each layer, we’re crossing the output from the previous layer again with the original features x_0, allowing us to generate cross features of arbitrary order simply by stacking more cross layers. In the paper, the authors study the performance of DCN as a function of the number of cross layers on the Criteo Display Ads benchmark dataset, resulting in the following plot:

Interestingly, the performance of DCN appears to converge after stacking just about 2 cross layers, which could either indicate that there’s really no more juice to squeeze, or that the cross layer in DCN is not expressive enough to capture the additional information that exists in higher-order interactions.
Alas, as we’ll see in DCN-V2, the latter appears to be the case.
DCN-V2
The hypothesis in DCN-V2 (Wang et al 2020) is that modeling feature interactions with a simple cross weight vector w, as done in DCN, is not expressive enough, and we need to replace this weight vector with a weight matrix to unlock the full potential of higher-order feature interactions.
More specifically, the cross layer in DCN-V2 models the next layer l+1 as
where ⊙ is the element-wise product, and W is the cross matrix, replacing the cross vector w in DCN.
Here’s a visualization of DCN and DCN-V2:

The crux of this change is that by having the matrix W take the place of the vector w we can now model bit-wise interactions, that is, interactions of certain positions (“bits”) of the feature vector. This fine-grained interaction modeling, which was not possible with the first version of DCN, greatly enhances the expressiveness of the learned feature crosses and hence modeling accuracy, so the hypothesis.
And indeed, the hypothesis was shown to hold empirically. Unlike DCN, DCN-V2 still shows improvements even when stacking up to 4 cross layers, as can be seen in the blue curve in the following plot.

It gets even better though. Enter DCN-Mix, introduced in the same paper.
DCN-Mix
DCN-Mix takes DCN-V2 and adds two optimizations on top of it, namely low-rank factorization and Mixture of Experts (MoE).
Low-rank factorization means that we approximate the cross matrix W (with dimension k*k) as
W = UxVwhere U has dimension k*r and, V has dimension r*k, and the hyperparameter r is the rank of this approximation. The underlying hypothesis behind this approach is that the cross matrix W has low intrinsic rank: in fact, DCN-Mix collapses back into DCN in the extreme case of r=1.
MoE in this context means that instead of adding single cross matrix W per layer, we add multiple cross matrix experts and combine them with a gate, as illustrated below. The intuition behind this change is that each expert will end up learning the optimal cross feature matrix on a particular domain of the input data, resulting in better overall performance compared to a single expert that tries to learn everything.

Putting everything together, a single cross layer in DCN-Mix performs the following transformation:

where
x_0 are the original features, and x_l are the features in cross layer l,
G is the gating network,
E are the experts,
U and V are the low-rank approximations for the cross matrix W, and
b are the biases.
Using a stack of 3 cross layers with 4 experts and r=256, DCN-Mix beat DCN-V2 on the MovieLens benchmark dataset by 0.1% logloss, demonstrating the superior expressiveness captured by this Mixture of low-rank Expert architecture.
GDCN
GDCN (Wang et al 2023) is latest member of the DCN family and the current champion on the Criteo leaderboard with 0.8161 AUC, +0.09% more than its closest competitor. The key idea is to take the architecture from DCN-V2 and add an information gate (hence the G in the name) on top of each cross layer, as illustrated below:

This looks exactly like DCN-V2, with the only difference that each feature cross is multiplied (that’s the ⊙ symbol) with a dedicated gate value.
The underlying hypothesis is that not every cross feature is meaningful, especially if they’re generated in a brute-force way. In fact, as we keep adding cross layers, it’s guaranteed that we introduce more and more feature interactions that are really just noise. There’s a risk that the model may end up overfitting to these noisy features, which can eventually degrade model performance and hence make stacking more cross layers counter-productive. By adding the gates, so the hypothesis, we allow the model to filter out the noisy feature crosses and keep only the meaningful ones, improving performance overall.
And indeed, the hypothesis was shown to be correct. Using a stack of 3 cross layers, GDCN beat DCN-V2 by 0.17% logloss on the Criteo benchmark, making it the current champion on this dataset.
It is also instructive to take a look at the gate values that are learned during training. The plot below shows the information gate matrix W in the first layer of GDCN, where the axes are the features, and the color encodes the information gate value for each of the feature interactions.

The plot clearly shows that the information contained in brute-force feature crosses is sparse, not dense, which explains the superior performance of GDCN.
Summary
We’ve covered a lot of ground here, so let’s recap.
DCN was one of the first algorithms to replace the manual engineering of cross features in Wide&Deep-like models with an algorithm that exhaustively computes all possible crosses. The cross layers in DCN have two free parameters, the weight vector w and the bias vector b.
DCN-V2 replaced DCN’s crossing vector w with a crossing matrix W, which makes the cross layers more expressive and allows us to get further performance gains, in particular when stacking more layers. While in DCN we saw performance plateau after 2 layers, DCN-V2 allows us to stack 4 layers or even more and still see performance improvements.
DCN-Mix replaces the crossing matrix W with a more expressive mixture of low-rank experts which are combined using a gating network, beating DCN-V2 on the Movielens benchmark dataset.
GDCN adds an information gate on top of each cross layer in DCN-V2 which controls how much weight the model should assign to each feature interaction, preventing the model from overfitting to noisy feature crosses. GDCN is the current champion on the Criteo problem.

DCN is a very powerful family of neural network architectures and has enabled significant improvements in click prediction modeling. However, as we see in the screenshot above taken from the website PapersWithCode, accuracy starts to plateau and it’s getting harder and harder to beat SoTA (which, at the time of this writing, is still GDCN).
It will be very interesting to see which innovations come next in this domain, and whether the long reign of DCN will eventually come to an end.
would love to see 2025 version! has there been any new progress on this?