
User Action Sequence Modeling: From Attention to Transformers and Beyond
The quest to LLM-ify recommender systems


User action sequences are among the most powerful inputs in recommender systems: your next click, read, watch, play, or purchase is likely at least somewhat related to what you’ve clicked on, read, watched, played, or purchased minutes, hours, days, months, or even years ago.
Historically, the status quo for modeling such user engagement sequences has been pooling: for example, a classic 2016 YouTube paper describes a system that takes the latest 50 watched videos, collects their embeddings from an embedding table, and pools these into a single feature vector with sum pooling. To save memory, the embedding table for these sequence videos is shared with the embedding table for candidate videos themselves.
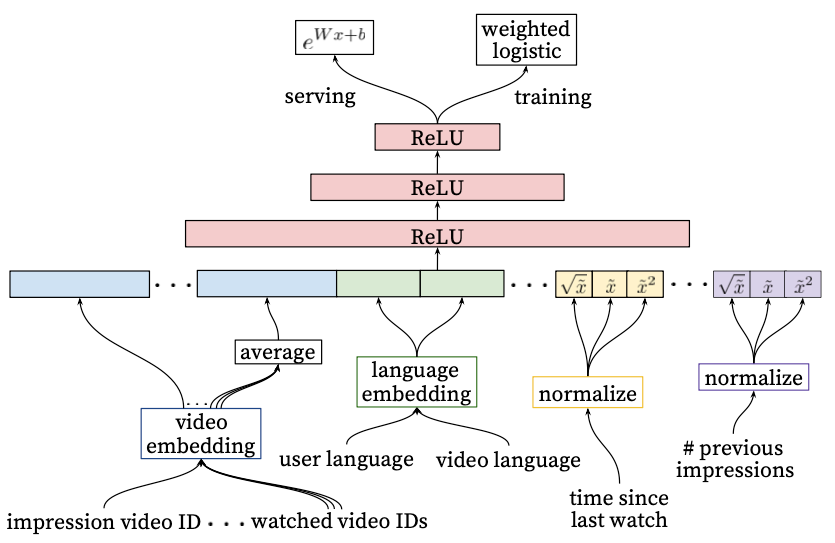
This simplistic approach corresponds roughly to a bag-of-words approach in the NLP domain: it works, but it’s far from ideal. Pooling does not take into account the sequential nature of inputs, nor the relevance of the item in the user history with respect to the candidate item we need to rank, nor any of the temporal information: an action minutes ago has different meaning than an action months ago, but for pooling they’re all the same.
These observations sparked a host of new research into borrowing elements from LLMs, which have had exceptional success in modeling word sequences, and see how well they translate into modeling user action sequences. LLMify recommender systems, if you will.
Let’s take a look at some of the breakthroughs and key ideas coming out of this stream of research, and how they transformed user action sequence modeling since YouTube’s 2016 paper.
Deep Interest Network (2018)

The key idea in the Deep Interest Network (DIN) — designed by Alibaba for e-commerce ads ranking — is to weight each item in the user action sequence depending on how relevant this item is to the candidate item to be ranked. The weight is determined by the activation unit, which takes as inputs the embeddings of both the candidate and the sequence item and outputs an activation score. Formally,

where e_i are the embeddings of the items in the user’s history, v_A is the embedding of the candidate ad, and a() is the activation unit.
This sounds a lot like cross-attention, a concept well known from LLMs, but it is not quite — there are two key differences:
In standard cross-attention, we’d compute the inner product between the two vectors, which would give us a measure of how similar the two vectors are overall. In contrast, DIN computes the outer product of the two vectors, which is a matrix, and then passes this matrix through another linear layer to compute the final output. The authors claim that outer products work better at capturing similarity with respect to diverse sets of interests than inner products.
The “attention” scores in DIN are not normalized with a softmax, which is standard practice in LLMs, such as to conserve the intensity signal of user interests, that is, taking into account not only the relative frequency of user interests but also the total count.
In order to make the model more stable and performant in practice, the authors of DIN introduce two additional novel modeling tricks, Dice and MBA.
Dice is an activation function that takes a standard PReLU activation (a smoothed version of ReLU), shifting the curve depending on the mean of the logits and squashing it depending on the variance of the logits, as such:

Formally,

where s is the input logit, E[s] and Var[s] are the mean and standard deviation over the batch, and epsilon is a small value (1e-8) added for stability. The underlying hypothesis is that this makes the model robust against changes in the absolute magnitude of logits —which may be expected due to the lack of softmax in the attention.
MBA, short for (mini) batch-aware L2 regularization, is an algorithms to approximate the L2 norm which is added as a regularization term to the loss during training. The key insight behind MBA is that, even though the total number of parameters in the model is very large, only a small fraction of the model parameters are being updated in each batch, in particular those of embeddings tables of ids present in that batch. Hence, when computing L2, we can cut corners by leaving out all the weights that are not present inside the batch, which makes the computation much faster.
Formally,

where the first sum runs over all parameters in the model, the second sum runs over all datapoints in the batch, and alpha_{m,j} is a binary function that’s 1 only if there is at least one training example using parameter j in batch m.

Ultimately, DIN + MBA + Dice beats a baseline model without sequence features by 11.65% AUC on Alibaba data, demonstrating the substantial performance gains from adding user sequence features using attention-like weights.
BERT4Rec (2019)
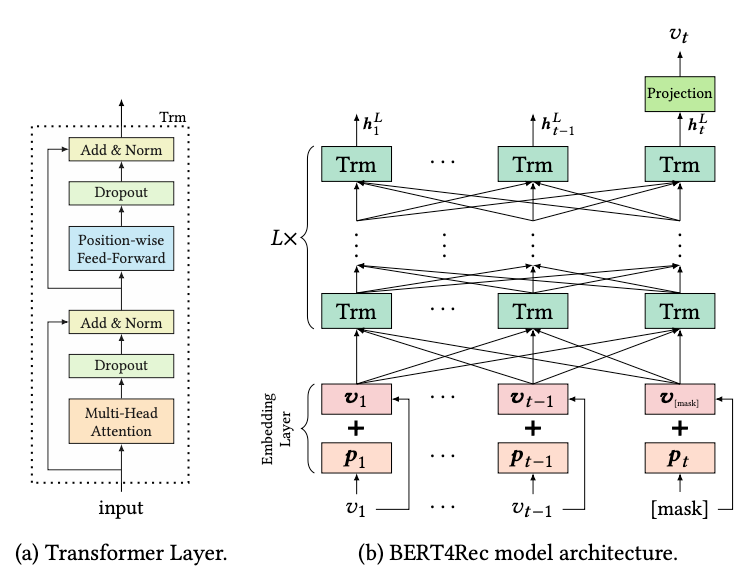
BERT4Rec is exactly what you may think: a BERT model that has been trained on user action sequences instead of word sequences. The main difference is the tokenization: in the case of user sequences, each "word" is a unique id that cannot be further broken down using sub-words. Hence, the vocabulary in BERT4Rec is orders of magnitude larger than the vocabulary in a standard BERT model, depending on the dataset we train on.
Just like the original BERT, BERT4Rec is trained using masked token prediction: it predicts the missing token (the id of the item in the user action sequence) given both the context to the right and to the left of it:

At inference time, we append the special token [mask] at the end of the user sequence and let the model predict the missing item.
The authors compare the performance of BERT4Rec against a suite of competitors on 4 benchmark datasets (Amazon Beauty, Steam, MovieLens-1M, MovieLens-20M), finding that it performs best among all methods and in terms of all evaluation metrics: on average, it gains 7.24% HR@10, 11.03% NDCG@10, and 11.46% MRR improvements against the strongest baselines. BERT4Rec showed for the first time that a deep bidirectional self-attention architecture, as populated by BERT and other models like it, translates remarkably well to user action sequences.
However, BERT4Rec does not scale well to longer sequences. First, longer sequences contain more information but also more noise, and the model could end up overfitting to that noise once the sequences get too long. Second, BERT’s self-attention is quadratic in complexity, introducing a computational bottleneck. Given this limitation, the authors find best performance with sequence lengths of 20-200, depending on the dataset in their experiments.
PinnerFormer (2021)

Similar to BERT4Rec, Pinterest’s PinnerFormer is a Transformer model that takes as inputs user action sequences. The novelty in PinnerFormer is its training paradigm: it makes predictions 28 days into the future, instead of prediction just the next action.
The key innovation to make this work is the introduction of the “Dense All Action Loss”: we sample random pairs of historic actions (those within the 1-year training window) and future actions (those within the 28-day prediction window), and then train the model to predict the future engagement given the sequence of all user actions that were known at the time of the historic action. To avoid leakage (i.e. feeding the model information from the future), we apply causal masking to the Transformer’s self-attention block, such that each action can only attend to past or present actions, not future actions.

Compared to simply predicting the next action, Dense All Action prediction results in a much larger number of training pairs that the model can learn from, improving predictive accuracy and preventing overfitting. In theory, this design should make the model more robust against staleness, and that’s precisely what the authors find: moving from realtime to daily batch inference drops Recall@10 by 13.9% when training using the SASRec objective (predicting just the next action in the sequence), but only by 8.3% when training using the Dense All Action objective.
Another notable innovation in the PinnerFormer is the way it samples negative examples during training. A common approach in recommender systems is in-batch negative sampling, which means that the positive training examples from one user are recycled as negatives for another user, eliminating the need for any other data. In contrast, PinnerFormer combines in-batch negatives with random negatives from the Pin Corpus, a diverse dataset covering Billions of Pins. Adding these random negatives allows the model to learn from a more diverse dataset which improves generalization, so the theory. In practice, adding these random negatives improved Recall@10 by 6.2%, compared to using just in-batch negatives.

Similar to BERT4Rec, PinnerFormer reaches a point of diminishing returns once sequences become too long. For example, doubling sequence lengths from 128 to 256 improves Recall@10 only marginally by less than 1%. This the same problem that plagued BERT4Rec: longer sequences also include more noise. In addition, longer sequences introduce higher computational demands as well due to the quadratic computational complexity of the Transformer’s self-attention. In practice, the authors were not able to scale PinnerFormer to sequences longer than 256.
HSTU (2024)

The assumption behind, BERT4Rec, PinnerFormer, and other generative models like them, is that the Transformer architecture, even though designed specifically for word sequences, can be re-used without major changes for user action sequences. One recent architecture that challenges this assumption is Meta’s HSTU, short for Hierarchical Sequential Transduction Units.
Architecturally, HSTU replaces the decoder-style Transformer block with the HSTU block, which contains 3 sub-layers that transform the input sequence X into an output sequence Y: (1) pointwise projection, (2) spatial aggregation, and (3) pointwise transformation:

where f denotes MLPs, Phi denotes non-linear SiLU activation, rab is a relative attention bias term taking into account both item positions (p) and time of interaction (t), and ☉ denotes the element-wise product.
The most obvious difference to a standard Transformer block is that HSTU splits the inputs not into 3 matrices K (keys), Q (queries), V (values), but into 4, adding the U matrix. This allows the model to learn a hierarchy of feature interactions of various depths — similar to the DCN architectural family — because the original feature is being passed back in the pointwise transformation step (3) in each HSTU block.
Another key distinction to Transformers is that the attention scores A(X) in the HSTU block are not normalized using softmax. We’ve seen this in DIN, and the reasoning here is the same: we want to the model to be sensitive to the intensity of inputs, that is, the total count of user actions, instead of just their relative frequencies. The underlying reason is that, unlike in LLMs, the corpus of tokens (i.e. ids) is not stationary but instead rapidly evolving, with new tokens constantly being introduced into and old tokens vanishing from the corpus. Softmax does not work well if the space it is normalizing over is constantly evolving.

With a number of engineering optimizations under the hood — including exploiting repetitiveness in sequences, custom-built GPU kernels, fused operations, and micro-batching — HSTU scales much better to longer user action sequences compared to standard Transformers. In practice, the authors find sub-linear computational complexity: increasing sequences lengths from 1K to 8K grows latency in a Transformer by a factor of 12.8, but in HSTU only by a factor of 5.
HSTU also achieves unprecedented accuracy on ranking tasks. In offline experiments, HSTU achieves 1.4% reduction in normalized entropy compared to a classic DLRM ranking model and 0.17% compared to a Transformer model.
Conclusion
The realization that “Attention is all you need” paved the way for the Transformer architecture, BERT, and LLMs as we know them today. Just like LLMs, recommender systems learn from sequences, which opens up the question of how much of the science behind modeling word sequences translates into modeling user action sequences.
DIN was among the first pieces of work that showed the potential of leveraging cross-attention with respect to the candidate instead of simply pooling all user sequences with equal weights. BERT4Rec demonstrated for the first time a ranking model trained using masked token prediction and bi-directional attention. PinnerFormer combined a Transformer architecture with the new Dense All Action loss, which resulted in a novel a modeling framework that’s remarkably robust against staleness. However, both BERT4Rec and PinnerFormer failed to scale to very long user action sequences: BERT4Rec reports best results with lengths up to 200, PinnerFormer with 256.
The game changed considerably with the introduction of HSTU, which showed for the first time that an architecture purpose-built for user action sequences beats the Transformer both with respect to scaling properties — the authors scale HSTU up to sequences lengths of 8K, an order of magnitude longer than BERT4Rec and PinnerFormer — as well as predictive accuracy.
Sequence modeling has been solved for word sequences ever since the introduction of the Transformer. For user action sequences, we’re really just getting started. It will be interesting to see how this space evolves over the coming years.
References
Deep Neural Networks for YouTube Recommendations, Covington et al 2016
Deep Interest Network for Click-Through Rate Prediction, Zhou et al 2017
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer, Sun et al 2019
PinnerFormer: Sequence Modeling for User Representation at Pinterest, Pancha et al 2022
Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations, Zhai et al 2024