
What Exactly Happens When We Fine-Tune Large Language Models?
Fine-tuning has long been the standard approach for adapting LLMs to downstream tasks, but only recent research is starting to reveal what's happening under the hood

 algorithm in artificial intelligence. The image features a digital, futuristic landscape with a large, central, glowing cube representing the BERT algorithm. Surrounding the cube are abstract representations of neural networks, with lines and nodes symbolizing the complex connections and data processing. In the background, there's a vast array of binary code raining down, symbolizing the massive data processing capabilities of BERT. The overall atmosphere is high-tech and innovative, highlighting the cutting-edge nature of the technology.")
Google’s BERT (Devlin et al 2019) was a paradigm shift in natural language modeling, in particular because of its introduction of the pre-training / fine-tuning paradigm: after unsupervised pre-training on a massive amount of text data, the model can be rapidly fine-tuned on a specific downstream task with relatively few labels because generic linguistic patterns have already been learned. This new paradigm paved the way for bigger and better LLMs, and remains one of the cornerstones of modern NLP.
Authors Jacob Devlin et al write that fine-tuning BERT is “straightforward”, simply by adding one additional layer after the final BERT layer and training the entire network for just a few epochs. The authors demonstrate strong performance on the NLP benchmark problems GLUE, SQuAD, and SWAG after fine-tuning for just 2-3 epochs with the ADAM optimizer with learning rates between 1e-5 to 5e-5, a recipe that has been commonly adopted within the research community.
Because of its remarkable success, this pre-training / fine-tuning paradigm has become a standard practice in the field, and is only gradually being replaced by newer techniques such as LoRA. However, from a science point of view we don’t actually understand the fine-tuning process very well. What layers change during fine-tuning? Why do we need to fine-tune at all, as opposed to simply using pre-trained embeddings as features? How stable are the results? And what exactly is the model learning during fine-tuning?
Let’s dive into some of the more recent “BERTology” research that followed the original BERT paper.
Which layers change during fine-tuning?

The intuition behind BERT is that the early layers learn generic linguistic patterns that have little relevance to the downstream task, while the later layers learn task-specific patterns. This intuition is in line with deep computer vision models, where the early layers learn generic features such as edges and corners, and the later layers learn specific features, such as eyes and noses in face detection.
This intuition has been experimentally confirmed by another Google team, Amil Merchant et al (2020), in their work “What Happens To BERT Embeddings During Fine-tuning?” One of their techniques is called partial freezing: they keep the early BERT layers frozen during the fine-tuning process, and measure how much the performance on the downstream task changes when varying the number of frozen layers. They show that the performance on both MNLI and SQuAD tasks does not notably drop even when freezing the first 8 of the 12 BERT layers (i.e. tuning only the last 4).
This finding corroborates the intuition that the last layers are the most task-specific, and therefore change the most during the fine-tuning process, while the early layers remain relatively stable. The results also imply that practitioners can potentially save compute resources by freezing the early layers instead of training the entire network during fine-tuning.
Do we need to fine-tune at all? Using pre-trained embeddings as features
Instead of fine-tuning, can we simply take the embeddings directly from the pre-trained BERT model as features in a downstream model? After all, fine-tuning is still computationally expensive because of the large number of free parameters in the BERT model, 110M in the case of BERT-base, and 340M in the case of BERT-large (and even larger in more recent models such as Llama and GPT-3). In addition, in applications with a large number of downstream tasks, it would be more economical to share a common set of weights that can be adjusted downstream.
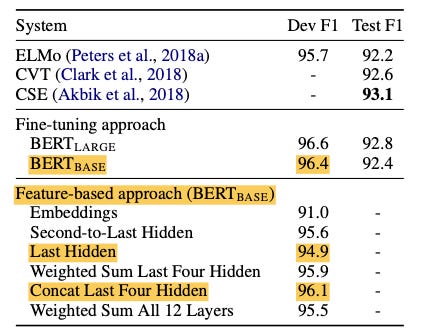
Devlin et al call this approach the “feature-based approach”, and they find that, indeed, it can perform close to a fine-tuned model. In particular, they feed the pre-trained BERT embeddings into a randomly initialized 2-layer BiLSTM network before the final classification layer, and measure the performance on the CoNLL-2003 named-entity-recognition benchmark problem set. Interestingly, they find that using the second-to-last hidden BERT layer works better than the final layer, which indicates that final layer is perhaps too close to the pre-training task. In fact, the authors report the best results when using the all of the last 4 hidden layers as features: an F1 score of 96.1%, which is just 0.3% below the fine-tuned BERT model!
Researchers Matthew Peters et al (2019), in “To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks”, come to similar conclusions. They consider 5 different NLP tasks, and compare the standard fine-tuning approach with the feature-based approach, where they use all 12 BERT layers as features in a downstream neural network model. They find that for tasks around named entity recognition, sentiment analysis, and natural language inference, the feature-based approach performs close (within 1% accuracy) to the fine-tuned model. The exception is the semantic text similarity task, where fine-tuning works much better (by 2–7%) than the feature-based approach, perhaps because this particular task is the least similar one with respect to the pre-training tasks.
The fine-tuning instability phenomenon

One of the problems with BERT is what has become known as the fine-tuning instability phenomenon: researchers observed that starting the fine-tuning training job with different random seeds leads to vastly different results, some of which can be poor. To account for this instability, some practitioners recommend running many fine-tuning jobs with different seeds and picking the best one on a hold-out set, a practice that would be unacceptable to any serious scientist.
Why is fine-tuning BERT so brittle? This question has been studied by 2 groups, Marius Mosbach et al (2020), in their work “On the stability of fine-tuning BERT”, and Tianyi Zhang et al (2020), in “Revisiting Few-sample BERT Fine-tuning”, both with similar conclusions.
First, there’s the question of the optimizer. The original ADAM optimizer includes a “bias correction term”, a term that implicitly adds a warm-up mechanism, effectively reducing the learning rate at the beginning of the training process. However, in the Tensorflow implementation of BERT, the authors excluded this term. Both Mosbach et al and Zhang et al showed that this explains part of the fine-tuning instability: after adding the bias correction term back in, the fine-tuning results are more stable, presumably because of the implicit warm-up phase added by this term.
Second, there’s the number of training epochs. Both Mosbach et al and Zhang et al show that the fine-tuning instability goes away simply when training for more than the “standard” 3 epochs, as done in the Devlin et al paper — Mosbach et al even recommend fine-tuning for 20 epochs! Intuitively, this result makes sense: even if we pick the worst possible seed, we should be able to converge to the same global potential minimum that we can reach from the best possible seed, it will just take longer to get there.
The 3 phases of fine-tuning

During fine-tuning, are LLMs actually learning broad patterns in the data, or are they simply memorizing individual training examples?
In the 2022 paper “Memorisation versus Generalisation in Pre-trained Language Models”, authors Michael Tänzer et al designed a clever experiment to find out. They started with an entirely noise-free training set — CoNLL03, a named-entity-recognition benchmark dataset — and then gradually introduced more and more artificial label noise. Comparing the learning curves for the train and validation sets as a function of label noise allowed them to determine the point at which the model starts memorizing training examples, which can be identified by a sudden drop in validation accuracy.
Based on the results, the authors show that fine-tuning BERT consists of 3 distinct phases:
Fitting (epoch 1): the model learns simple, generic pattens that explain as much of the training data as possible. During this phase, both training and validation accuracies increase.
Setting (epochs 2–5): there are no more simple patterns left to learn. Both training and validation performance saturate, forming a plateau in the learning curve.
Memorization (epochs 6+): the model starts to memorize specific training examples — including noise — which improves training performance but degrades validation performance, depending on how much noise exists in the data. The model is overfitting.
The results validate Devlin’s choice of fine-tuning for just 2-3 epochs, landing right in the setting phase, but contradict Mosbach’s 20-epoch recommendation, which would put us firmly into memorization territory. When fine-tuning BERT, fewer epochs appear to be a safer choice to prevent the model from simply memorizing individual training examples.
Conclusion
Let’s recap:
BERT’s layers are hierarchical. Early BERT layers learn more generic linguistic patterns, the equivalent of edges and corners in deep vision models, while the later BERT layers learn more task-specific patterns.
Fine-tuning is not always necessary. Instead, the feature-based approach, where we simply extract pre-trained BERT embeddings as features, can be a viable, and cheap, alternative. This works better when using not just the final layer, but at least the last 4, or all of them.
Fine-tuning is brittle when following the recipe from Devlin et al. This fine-tuning instability has been shown to go away when training for a larger number of epochs, and when using the original ADAM optimizer instead of the modified version used in Devlin et al.
Fine-tuning can be divided into 3 phases: fitting, during which the model learns simple patterns, setting, during which both training and validation performance plateau as there are no more simple patterns left to learn, and memorization, during which the model starts memorizing individual training examples, including noise.
Fine-tuning has been a cornerstone of NLP for around half a decade. From a practical point of view, it is one of the most broadly adopted techniques in modern ML applications. From a science point of view, we’ve only scratched the surface about what’s happening under the hood.