

Experts Everywhere: How Mixtures of Experts Turbocharge Large Language Models
Experts Everywhere: How Mixtures of Experts Turbocharge Large Language Models
The creative new ways to MoE-ify LLMs, from Switch Transformers to Mixtures of Depths

 technology in AI. The image should feature a futuristic, digital landscape with various sections representing different domains of expertise, each manned by a distinct robotic figure symbolizing an expert. These robots should be interconnected by glowing data streams, symbolizing the sharing and routing of information between them. The background should have a complex, circuit-like pattern, reflecting the intricate nature of AI networks. The overall color scheme should be dominated by blues and cyans, with accents of silver and white to suggest advanced technology and innovation.")
Mixtures of Experts (MoE) — a class of algorithms that partition a complex problem into independent sub-domains that can be solved with local experts — is an idea that traces back more than 3 decades ago to original work co-authored by none other than the godfather of AI himself, Geoffrey Hinton. The 1991 paper titled “Adaptive Mixtures of Local Experts” showed how an MoE model solves a vowel classification problem, with each expert specializing in learning different decision boundaries from the training data.
MoE is suitable wherever the problem we’re trying to solve is complex but can be broken down into more manageable sub-problems, making it particularly useful for language problems. This usefulness was first demonstrated in the 2017 work “Outrageously large neural networks” (Shazeer et al 2017), which describes a 137-Billion parameter LSTM model with thousands of sparsely activated experts that achieves new SOTA performance on the Billion-words language modeling benchmark.
The success of this work spawned renewed interest into integrating MoE with language models, eventually leading to new breakthroughs in the field such as the Switch Transformer (2022), Mixture of Attention heads (2022), SwitchHead (2023), and Mixture of Depths (2024).
Let’s take a look at how this new generation of models integrate MoE into LLMs.
Switch Transformer (2022)
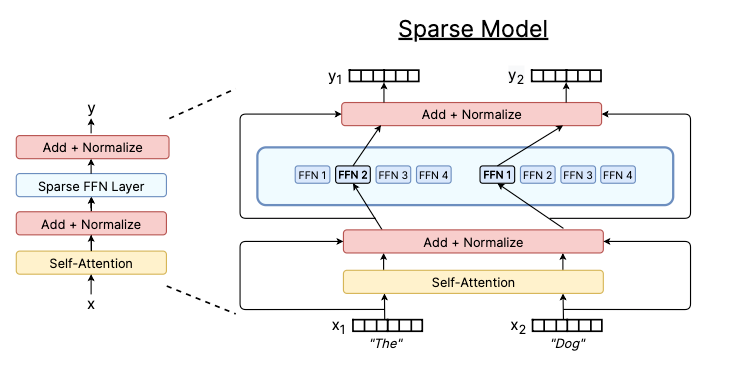
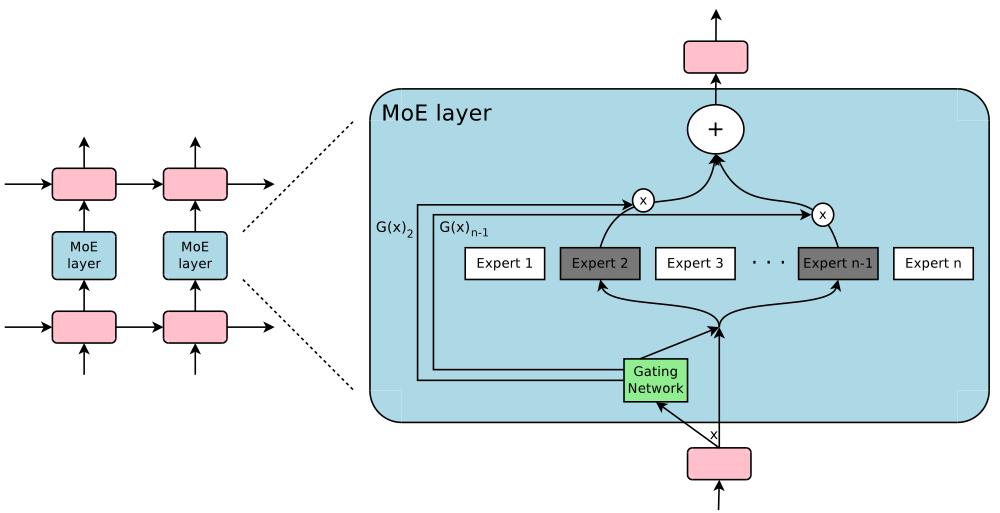
The Switch Transformer (Fedus et al 2022) was the first demonstration of the usefulness of sparsely gated MoE in a modern, decoder-only, Transformer model. The key idea in the Switch Transformer is to replace the single FFN module in the Transformer block with multiple FFN “experts”, where a router determines which token to send to which expert, a design also known as hard routing. In theory, this design allows us to scale up modeling capacity with O(1) computational complexity — we just need the extra space to store all of the expert weights.
One of the difficulties in hard routing is that the router may simply end up sending all tokens to a single expert, thus introducing a computational bottleneck. We can solve this problem by defining expert capacity, i.e. the number of tokens experts are allowed to process), as
capacity = f x T/Ewhere T is the number of tokens in the input sequence, E is the number of experts, and f is a free hyperparameter that we can tune. For example, with T=6, E=3, and f=1, we’d allow the router to send up to 2 tokens to each expert: if we send more, we drop the extra tokens, and if we send less, we use padding to ensure consistent tensor shapes.
The capacity factor f thus introduces a trade-off: too large, and we waste compute resources by excessive padding, too small, and we sacrifice model performance due to token dropping. In the paper, the authors find the best performance with a relatively low capacity factor of f=1, indicating that it’s better to optimize for resource utilization even at the cost of aggressive token dropping.
Ultimately, the authors show that a T5-based Switch Transformer with 64 experts in each block achieves the same modeling performance with the same number of FLOPs as a standard T5 model, but 7x faster!
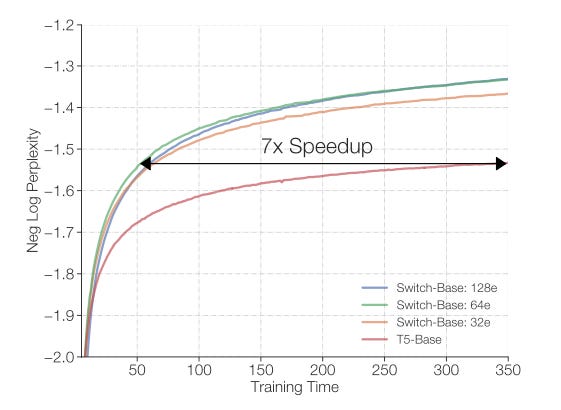
At first glance, this looks like magic. How is it possible to be that much faster with the same amount of FLOPs? The answer is that the Switch Transformer spends those FLOPs in the right places, which is possible due to the sparse activation of experts.
MoA: Mixture of attention heads (2022)
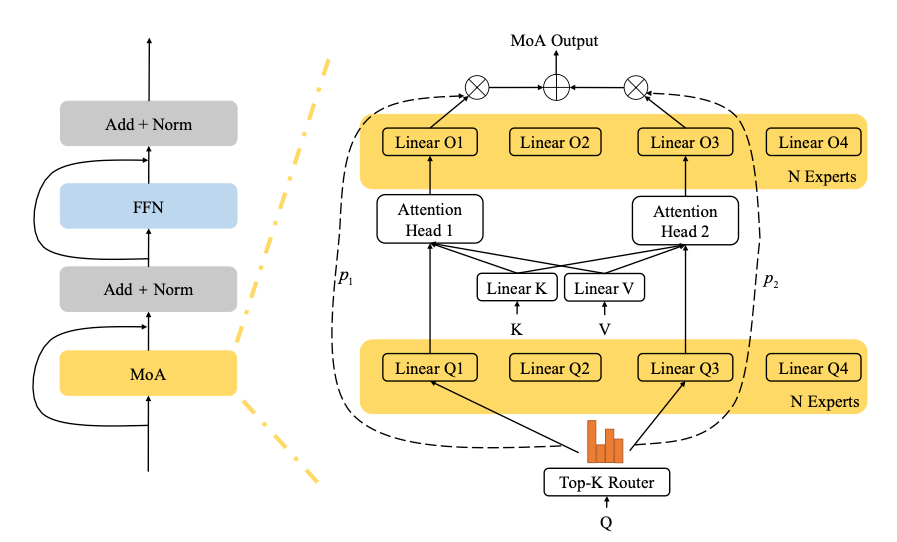
In standard multi-headed self-attention, we simply concatenate the outputs from all heads. The key idea in Mixture of Attention heads (MoA), introduced in Zhang et al 2022, is to instead treat each head as an expert, and combine their outputs using a top-K router.
In order to reduce computational complexity, the K and V projection matrices are shared across all experts, while each expert has its own Q matrix. In addition, we also replace the single output projection matrix O with experts that are tied to the Q experts. For example, if the router selects expert number 3, the input sequence will be passed through the shared K and V projection matrices, but only through the third Q and O matrices.
One problem with training MoA is that, similar to the Switch Transformer or the outrageously large MoE-LSTM model, the router tends to collapse into sending all tokens to the same expert. The authors solve this problem by introducing two auxiliary loss terms — load balancing loss and router-z loss — the weights of which need to be tuned for optimal performance.
The authors propose two different variants of the model that are built on top of the Transformer base model (Vaswani et al 2017) with 8 heads,
MoA Base: 8 experts with K=8 and 128 embedding dimensions.
MoA Big: 32 experts with K=16 and 256 embedding dimensions. Here, only half the experts are activated at any given time.
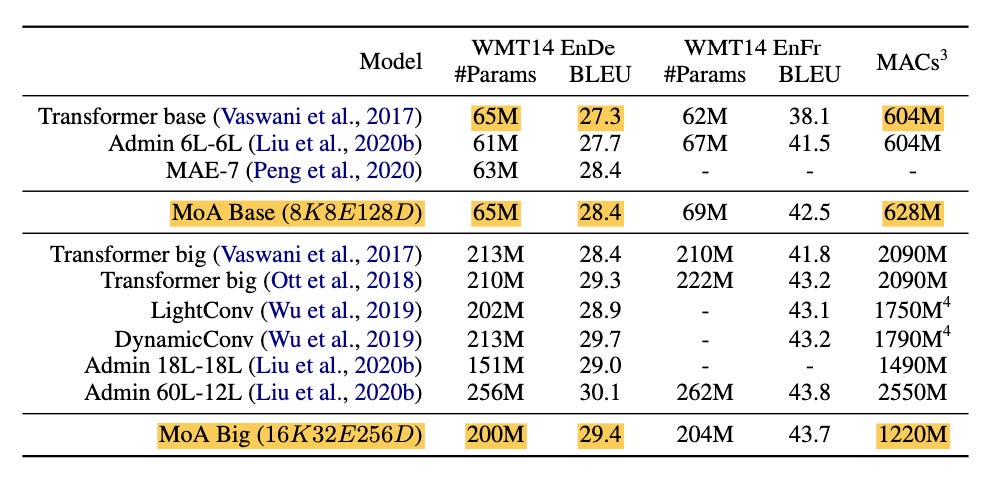
Empirically, MoA Base outperforms the standard Transformer by 1.1 BLEU points on the WMT15 English-German translation problem dataset with the same number of parameters and roughly the same amount of compute. Again, this may seem like magic: how can we improve performance without adding compute? The answer is that we haven’t really added any additional operations in this particular experiment (both models have 8 heads), instead we’re simply combining the existing heads more efficiently.
The authors also show that MoA scales well with the number of experts: MoA Big (with 4X the number of heads) outperforms the Transformer by 2.1 BLEU points with a just about 3X more parameters and 2X the amount of compute. This sub-linearly scaling is possible because we use sparse top-K instead of dense routing.
SwitchHead (2023)
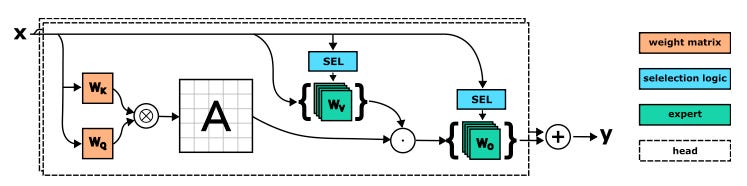
Unlike MoA, the key idea in SwitchHead (Csordás et al 2023) is to preserve the existing heads as they are, but to introduce MoE into the projection matrices in each head. The hypothesis is that we should be able to substantially reduce the number of heads while adding modeling capacity where it is actually needed and hence reduce computational complexity.
In particular, SwitchHead uses a only 2 attention heads but additionally it replaces the value (V) and output (O) projection matrices in the attention module with 5 hard-routed experts, i.e. only a single expert is activated for each token. With this configuration, SwitchHead beats the TransformerXL model with 10 heads by 0.04 perplexity points. In addition, because SwitchHead has 5x fewer heads, it also requires around 4.4x less memory and 2.6x fewer compute operations.
You may be wondering why the authors chose to MoE-ify V and O, but not K or Q. The answer is that authors simply tried all possible combinations and found the best performance (i.e., lowest perplexity) with this particular configuration. Indeed, MoE-ifying just the O matrix works almost as well (to within 0.03 perplexity points), which shows that the output projection matrix O is perhaps the most MoE-ifiable piece of the self-attention module — which also helps explain the success of MoA.
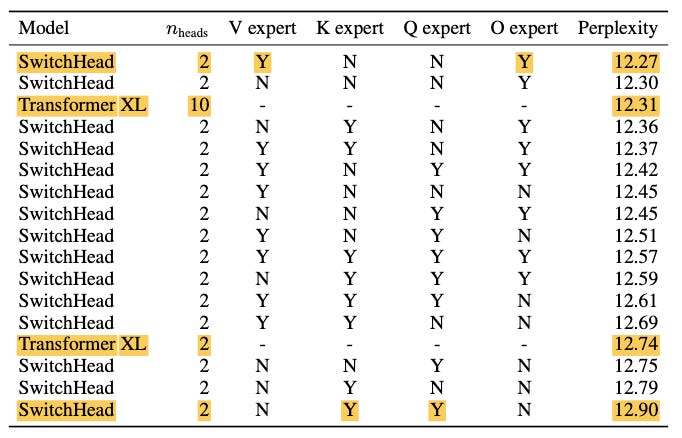
The authors find that MoA can outperform SwitchHead, but only at a price of using significantly more compute and memory. In particular, MoA with 8 heads has a 0.14 lower perplexity, but at the expense of 2.3X more memory and 3.3X more compute. With a more comparable setup (both with just 2 heads, resulting in roughly similar computational complexity), SwitchHead beats MoA by 0.38 perplexity points.
MoD: Mixture of Depths (2024)
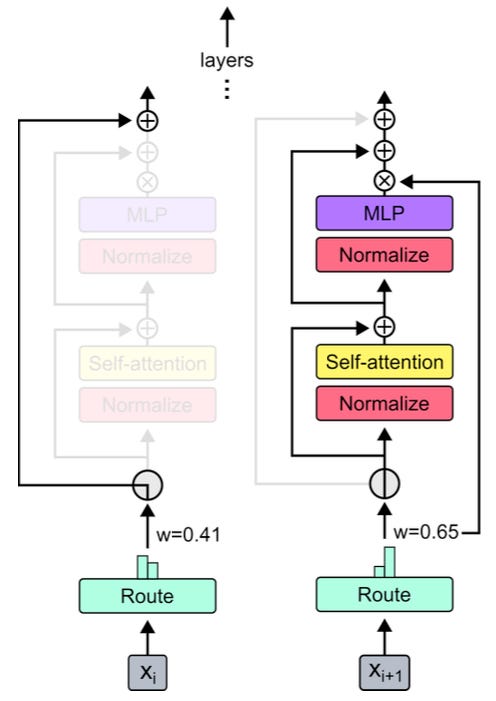
Unlike the Switch Transformer, which integrates MoE into the MLP module, or SwitchHead and MoA, which integrate MoE into the attention module, Mixture of Depths (MoD), proposed in Raposo et al 2024, integrates MoE into the skip connections. This means that for each token in the input sequence a router determines whether that token will be passed through the Transformer block consisting of self-attention and MLP layers, or whether it will skip that block.
The hypothesis behind MoD is that different tokens have different degrees of difficulty for the model to learn. Therefore, it makes sense for the compute budget to be adaptive: more compute for the harder-to-learn tokens, and less compute for the easier ones. The trick, then, is to route the former through the regular Transformer block and the latter only through the skip connection.
Formally, the output x of layer l+1 at index i is:
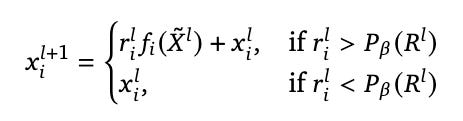
where r is the router output, f is the combination of the self-attention and MLP modules, P is the percentile threshold, and the tilde denotes all inputs that fall within that threshold. Put simply: if the router output is high, we send the token through f — if it’s low, we don’t.
Which introduces the question of where we should set the threshold for determining which token goes where. In MoD, we determine this threshold using block capacity: for each Transformer block, we decide ahead of time what ratio of tokens in an input sequence we want to allow in that block. For example, if capacity is 50%, we set the threshold to be the 50th percentile of all router outputs, hence resulting in 50% of tokens bypassing the block. Technically, this particular design choice is a form of expert choice routing.
Empirically, the authors find that a capacity ratio of 12.5% in every other Transformer block works best, that is, in every other block 87.5% of tokens bypass that block. This alone is a very interesting result, indicating that almost half of the FLOPs done by a Transformer are useless. Even more interesting is that the distribution of gate value across all layers is bi-modal, with most tokens either skipping all skippable blocks, or going through all skippable blocks — which confirms the existence of a dichotomy of training examples: “easy” and “hard”.
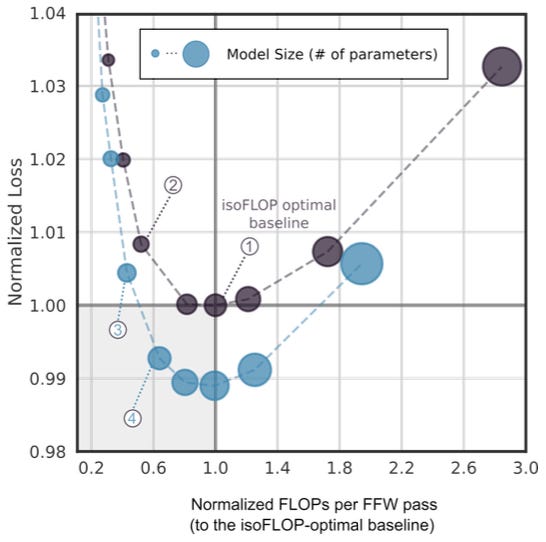
MoD allows us to either save FLOPs (by removing computations from an existing Transformer model with equal loss) or improve predictive accuracy (by adding modeling capacity with FLOPs parity). In experiments, the authors show that they can either get 50% savings in compute with equal loss, or 1.5% better loss with equal compute — an impressive demonstration of the adaptive computation that’s enabled by the MoD architecture.
One interesting technical detail in MoD is that we can’t use a top-K algorithm directly in the router because it introduces non-causality, that is, it requires knowledge about the entire sequence at once. (Causality is critical for the fluency of text generation in decoder-style Transformer models.) The authors solve this problem by not using top-K directly, but instead using a small auxiliary MLP that learns to predict whether a token will be in the top-K or not. This turns out to be a relatively simple prediction problem that can be learned with upwards of 97% accuracy.
Conclusion
To summarize:
The Switch Transformer integrates MoE into the feed-forward module of the Transformer block, and achieves 7X speed-up compared to a standard Transformer model.
MoA (Mixture of Attention heads) integrates MoE into the Q and O projection matrices in the attention module, and outperforms the standard Transformer by 1.1 BLEU points on the WMT15 English-German translation problem dataset with the same number FLOPs.
SwitchHead integrates MoE into the V and O projection matrices in the attention module, which the authors find to be the best combination of projection matrices to MoE-ify (with O experts alone accounting for most of the gains). The advantage of SwitchHead is that it does not require a large number of heads: with just 2 attention heads, SwitchHead beats MoA with 8 heads by 0.38 perplexity points.
MoD (Mixture of Depths) integrates MoE into the skip connections, allowing tokens to bypass a Transformer block entirely, which enables adaptive computation depending on the difficulty of the inputs. In experiments, the authors show that they can either get 50% savings in compute with equal loss, or 1.5% better loss with equal compute, compared to a standard Transformer model.
These are exciting times. LLM-MoE-ification has rapidly become a new lever to turbocharge model performance, and it will be very interesting to see what comes next. Indeed, there’s nothing stopping us from combining multiple MoE integration points in a single model: for example, Raposo et al introduce “MoDE”, which combines MoD with a Switch-Transformer-like architecture, resulting in even better performance that either of the two alone.
MoE is celebrating its 33rd anniversary this year; for today’s ML researchers, the work is really just getting started.
💪 Get 30% off my e-book Machine Learning on the Ground using the discount code MLFRONTIERS.