
Hierarchical Mixtures of Experts: The Next Generation of Multi-Task Learners
Meet HoME, Kuaishou's latest multi-task ranking model

 model, depicting multiple layers of expert models connected in a structured tree-like hierarchy. At the top, a master gating network dynamically selects between different expert pathways. Each expert model is illustrated as a glowing neural node, interconnected with others, forming a cascading decision process. The background is a deep, futuristic blue with digital neural network patterns, emphasizing the AI-driven complexity of the system. The image is purely graphical with no text or labels present.")
Modern recommender systems typically learn to predict multiple user engagements with a single model and then combine all of these predictions into a final rank (for example using a weighted sum).
This opens up the question of how to build neural architectures that can learn optimally even if different tasks pull the model weights in different directions, creating conflicting gradients also known as “negative transfer”. For a long time, the gold standard has been Google’s MMoE, short for multi-gated Mixtures of Experts (Ma et al 2018), a variant of MoE where all experts are shared across all tasks, but each task has its own gate. This allows the model to learn task-specific combinations of experts, so that, at least in theory, similar tasks can end up sharing the same experts, hence avoiding negative transfer.
In practice though modelers soon found that MMoE would oftentimes collapse into a state where all tasks use the same, single expert, not much different from the “shared-bottom” architecture that MMoE was supposed to replace. This is a problem not only because it re-introduces negative transfer but also because we’re wasting compute and memory resources on experts that are doing nothing useful. Even worse, experts with zero weights receive no gradient updates so that the model cannot get out of this local minimum. This empirical finding motivated the development of a new generation of multi-task model architectures that are smarter at allocating tasks to experts and avoid the collapse problem.
One relatively recent work in this domain is Kuaishou’s HoME, short for “Hierarchy Of Multi-gated Experts” (Wang et al 2024), which, according to the authors’ experiments, seems to be the best multi-task learner in the industry today. Let’s take a look.
Taxonomy of multi-task learning architectures

First though, let’s understand the taxonomy of existing multi-task architectures. In order of complexity, we have:
Shared Bottom: a single MLP with a single input (typically an embedding produced by an earlier part of the model), the output of which is being passed into multiple task heads at the same time. Each task head computes a sigmoid-transformed logit corresponding to the probability of the event it is trying to predict. Gradients flow back through the MLP from all of the task heads.
MMoE: instead of a single MLP, we introduce multiple MLP “experts”. Each task head takes as input a weighted sum of the expert outputs, where the weights are determined by the task’s gating network. By allowing each task to have its own gate, similar tasks can be grouped into similar experts, so the theory.
ML-MMoE: same as MMoE, but with multiple layers, adding more expressiveness to the model.
CGC (“customized gate control”): same as MMoE, but in addition to shared experts we add task-specific experts, one per task. The theory is that by allowing the model to have specialized experts, the model can better capture task-specific patterns while still leveraging shared knowledge across tasks. In Tang et al 2020, the authors found that CGC beats MMoE by 0.3% AUC on “view-through rate” (play threshold of a video exceeding a certain time) prediction on Tencent’s data.
PLE (“progressive layer extraction”): a two-layer CGC model, from the same authors as CGC.
Problems with existing approaches
Alas, not even CGC and PLE are good enough, so the claim in Kuaishou’s most recent work. The authors of HoME identify 3 distinct problems with the existing paradigms.
Problem #1: Expert collapse

Expert collapse means that certain experts dominate the learning process, while others become inactive or underutilized. This occurs because the gating network tends to favor a subset of experts, leading to:
loss of diversity in expert representations,
poor generalization, since only a few experts contribute to the predictions, and
redundant experts, where some experts are effectively ignored, wasting computational resources.
Because an expert with zero gate weight receives no gradient updates, the model cannot recover from this state on its own and end up trapped in a local minimum.
Problem #2: Expert degradation
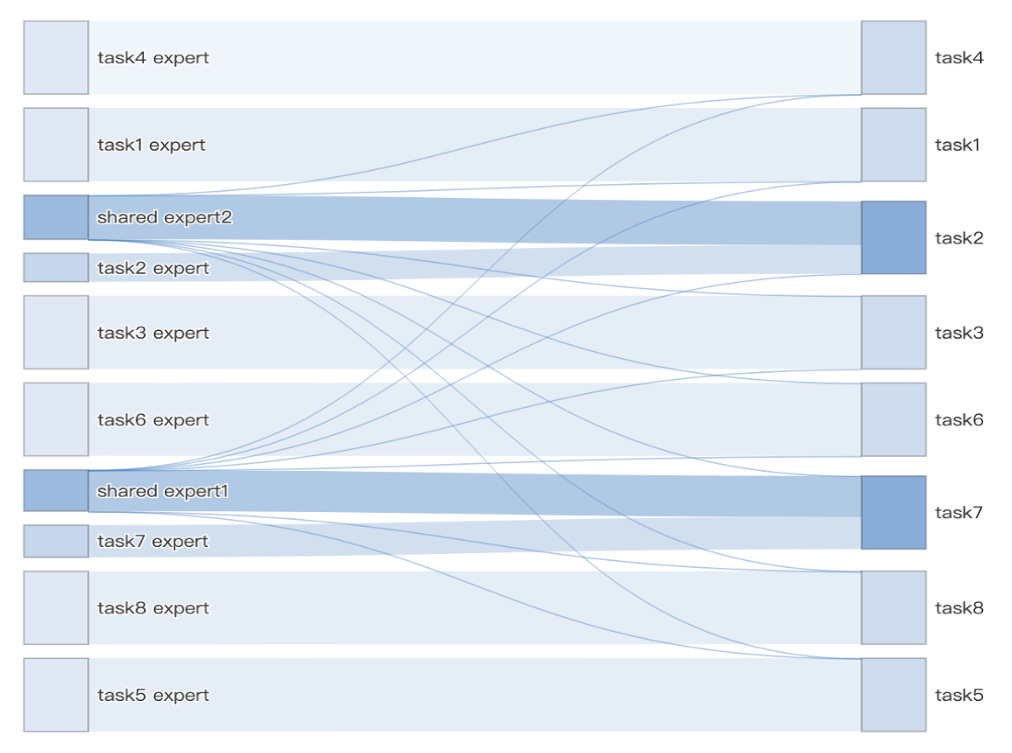
Expert degradation occurs when shared experts in CGC are being “monopolized”, which means that most gate weights on that experts come from a single task, typically the one with the highest response rate. This is another local minimum we want to avoid because it prevents the model from learning shared patterns across tasks.
Problem #3: Expert underfitting

Expert underfitting is the opposite problem of expert degradation: it means that certain tasks fail to use their task-specific expert, instead relying mostly on the shared experts. This is a particular problem for sparse tasks (such as “comment” or “share”) where the response rates are low, resulting in low activation of the task-specific expert.
HOME architecture

The premise behind HoME is that we can avoid these 3 problems (expert collapse, expert degradation, and expert underfitting) with a more careful design of the shared expert architecture.
Architecturally, HoME is a two-layer MMoE with the addition of (1) expert normalization, (2) expert hierarchy, (3) meta abstraction, and (4) information gates. Let’s look into these pieces one by one.
Trick #1: Expert normalization
The first trick is so simple that it may be hard to believe that this has been missed in earlier work: Batch Norm. This means the output from each expert in each batch has a normal distribution with a zero mean and unit variance. This helps prevent collapse because it ensures that even though an expert is being under-utilized by the gate, the expert activations remain at a stable scale, preventing it from becoming completely inactive over time.
The “HoME expert” can thus be written as
HoME_Expert ( · ) = Swish(Batch_Norm( MLP ( · ) )) ,where Swish is the activation function, which is authors find to work better than the standard ReLU activation (which was used in the original MMoE work).
Trick #2: Expert hierarchy
The second trick is to introduce an expert hierarchy consisting of 3 classes. In addition to specialized experts (one per task) and global experts (shared across all tasks), we have “group experts”, that is, experts that are shared across groups of tasks. This is useful because it allows for more control in how experts are being shared across tasks, but it also requires domain expertise because we need to define these groups ahead of time.
In Kuaishou’s case, the authors use two distinct event groups:
passive engagements, such as watch time or watch completion rate,
active engagements, such as Like, Comment, Share, or Follow.
This means that in Kuaihou’s HoME model, in addition to global and local experts, we have two group experts, namely an “active engagement expert” and a “passive engagement expert”.
Trick #3: Meta abstraction layer
The effectiveness of stacking multiple MMoE layers was first demonstrated in Tang et al, who stacked 2 CGC layers to create PLE.
HoME follows the same principle by using two stacked MMoE layers, which the authors call the “meta abstraction layer” and the “task layer”. These two layers differ in the following 2 ways:
outputs: the task layer outputs sigmoid-normalized logits (i.e. probabilities), while the meta layer outputs embeddings.
expert hierarchies: the task layer has 3 classes of experts (task-specific, group, and global), while the meta layer only has 2 classes (group and global).
The motivation behind this design is to allow for progressive feature refinement where the first layer learns more general patterns at the group and global level, and only the second layer learns task-specific patterns. This helps with expert degradation and expert underfitting because it forces the model to learn task-independent patterns first, so the theory.
Trick #4: Information gating
HoME introduces information gates at various points in the network which control the flow of information dynamically. These gates xhelp regulate how much of the input is passed to each expert and how much of the expert's output is retained before reaching the next layer.
The two types of information gates in HoME are:
Feature-Gates – applied to the experts’ inputs, and
Self-Gates – applied to the experts’ outputs.
The underlying hypothesis is that information gating supports expert specialization because it limits gradients from an expert flowing into parts of the embedding space that are outside of that expert's domain of expertise. This improved specialization can in turn help with expert degradation and expert underfitting.
Experimental results

HOME brings significant improvements over MMoE on all 6 tasks (effective-view, long-view, click, like, comment, collect, forward, follow) in Kuaishou’s model. It also beats CGC and PLE on all 6 tasks. For example, on the effective-view prediction, the authors measure a 0.3% improvement in AUC over MMoE.
Based on ablation experiments, we are also able to say where exactly the gains are coming from. Looking at just the effective-view task,
0.1% comes from the added batch norm and Swish activation in the expert architecture,
another 0.1% comes from the expert hierarchy (as opposed to all experts being shared), and
another 0.1% comes from the information gates, with most of the effect coming from the feature gates.
In A/B tests, the authors measured 1% increase in total play time and 0.55% increase in total number of videos watched compared to their MMoE-based production model, a remarkable result. HoME has been widely deployed on various ranking surfaces at Kuaishou.
Coda
MMoE is a theoretically sound idea but it eventually failed in practice, perhaps because the authors did not foresee the large number and diversity of tasks predicted in modern ranking models. In fact, in the industry example given in the original MMoE paper, the authors modeled merely two tasks, “user engagement” and “user satisfaction”. For relatively simple problems like this, MMoE probably remains a good choice.
The journey from MMoE to HoME is a good example of the difficulty in making the model do exactly what we want it to do. Give it multiple gates and experts, and it will still use only one expert. Give a task both shared and dedicated experts, and it will use only one or the other, not both. It is easy to train models, but it is much harder to understand what exactly our models are doing, and why. Correcting unwanted behavior, as we’ve seen here, can take years of work. In the authors’ words:
“After launching the MMoE, we have tried several different changes to the multi-task modeling module in past years. But all ended in failure, including upgrading to two or more expert layers, extending more shared experts, introducing extra specific-experts, and so on.”
It will be interesting to see how this domain evolves. A few ideas that I think people will explore are:
adaptive expert selection: exploring mechanisms that dynamically adjust the number of experts assigned to each task based on real-time performance signals. For example, we could imagine a system that automatically allocates more experts to a task that becomes more difficult to predict over time.
automated group partitioning for the group experts instead of relying on heuristics.
sparse MMoE: it seems that no one has done this yet, but in principle we should be able to save considerable resources by replacing the soft routing in MMoE with a hard router, similar to the Switch Transformer.
Until next time!