
Breaking down Tencent's Recommendation Algorithm
Ads Recommendation in a Collapsed and Entangled World


“Bag of tricks” papers present not a single novel idea but instead aggregate a unique set of techniques and tricks that have been found to be useful in production. In contrast to more traditional “research-style” papers with a focus on a single hypothesis, the wealth of ideas found in these bags of tricks make them particularly useful for ML practitioners. Well-known examples for such works are YouTube’s “Deep Neural Networks for YouTube Recommendation” (Covington et al 2016), Google’s “Recommending What Video to Watch Next” (Zhao et al 2019), or Bytedance’s Monolith (Liu et al 2022).
The recent paper “Ads Recommendation in a Collapsed and Entangled World” (Pan et al 2024) gives us a rare glimpse into Tencent’s bag of tricks for ads ranking across their apps (WeChat, QQ, Tencent Video/News, Qzone, etc), covering questions on encoding for numeric and sequence features, tackling embedding dimensional collapse, interest entanglement in multi-task rankers, and more. Let’s take a look.
Sequence feature encoding
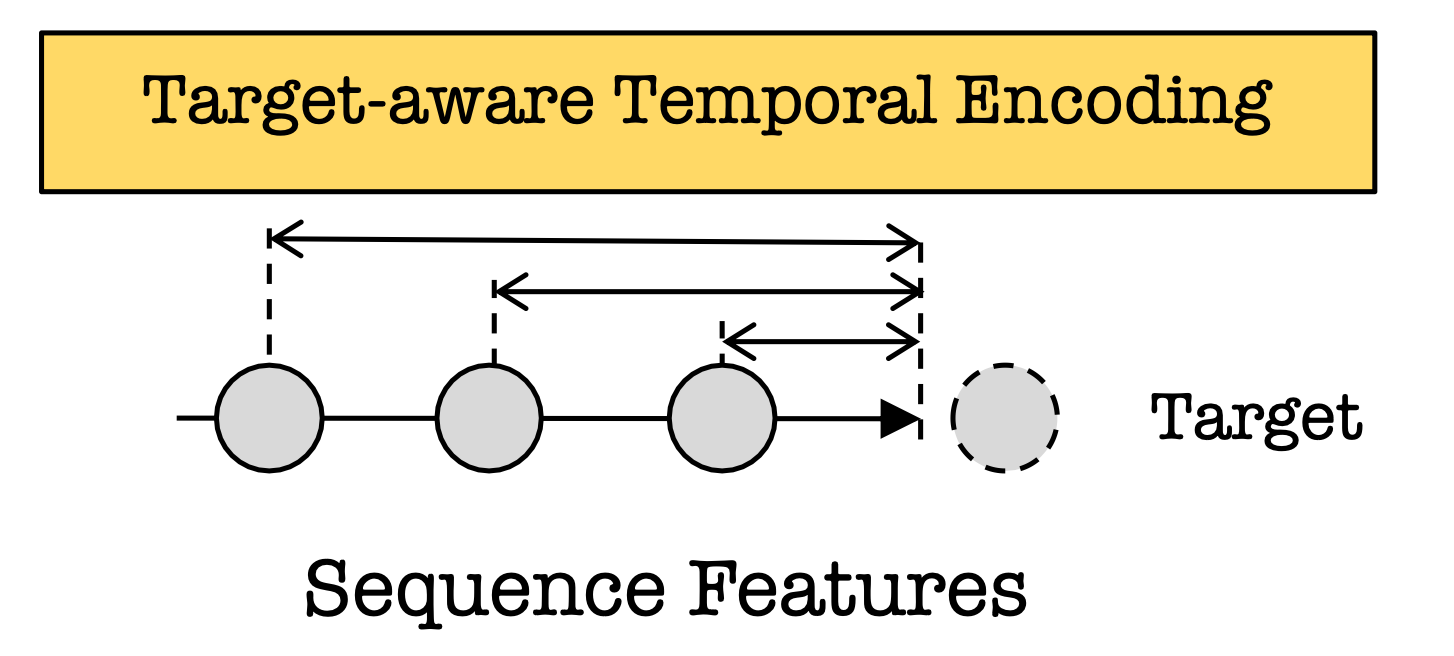
Similar to Kuaishou’s TWIN, Tencent relies heavily on Target Attention to encode sequential features, where the keys are the items in the user history and the target is the candidate item to be ranked. However, unlike TWIN, Tencent’s target-attention implementation TIM (“temporal interest module”) accounts not only for the semantic correlations but also temporal correlations.
Specifically, TIM’s target embedding is
where
the sum is taken over all items in the user action history,
e_i and e_t are the user item and target item embeddings, respectively,
the first factor (alpha) inside the sum is the standard target attention between the user history item and the target, i.e. the normalized dot-product,
the second factor inside the sum is the “target-aware representation” of item i with respect to target t, i.e. the element-wise product of the target with the item,
p_i is the temporal embedding for item i, which is an embedding that corresponds to the relative time delta since the item was seen.
Hence, compared to standard target attention, TIM introduces two main novelties:
By pooling the target-aware item representations (instead of just the item representations themselves), TIM effectively acts like a feature interaction layer that generates interactions between user history item and the target.
Second, by incorporating the temporal embedding p_i, TIM takes into account all sorts of temporal correlations, such as users watching the same content at the same time of day, day of week, season, etc.
The authors explain that the introduction of TIM brought gains of 1.93% Gross Merchandise Value (GMV) in WeChat’s ads recommendations.
Numeric feature encoding
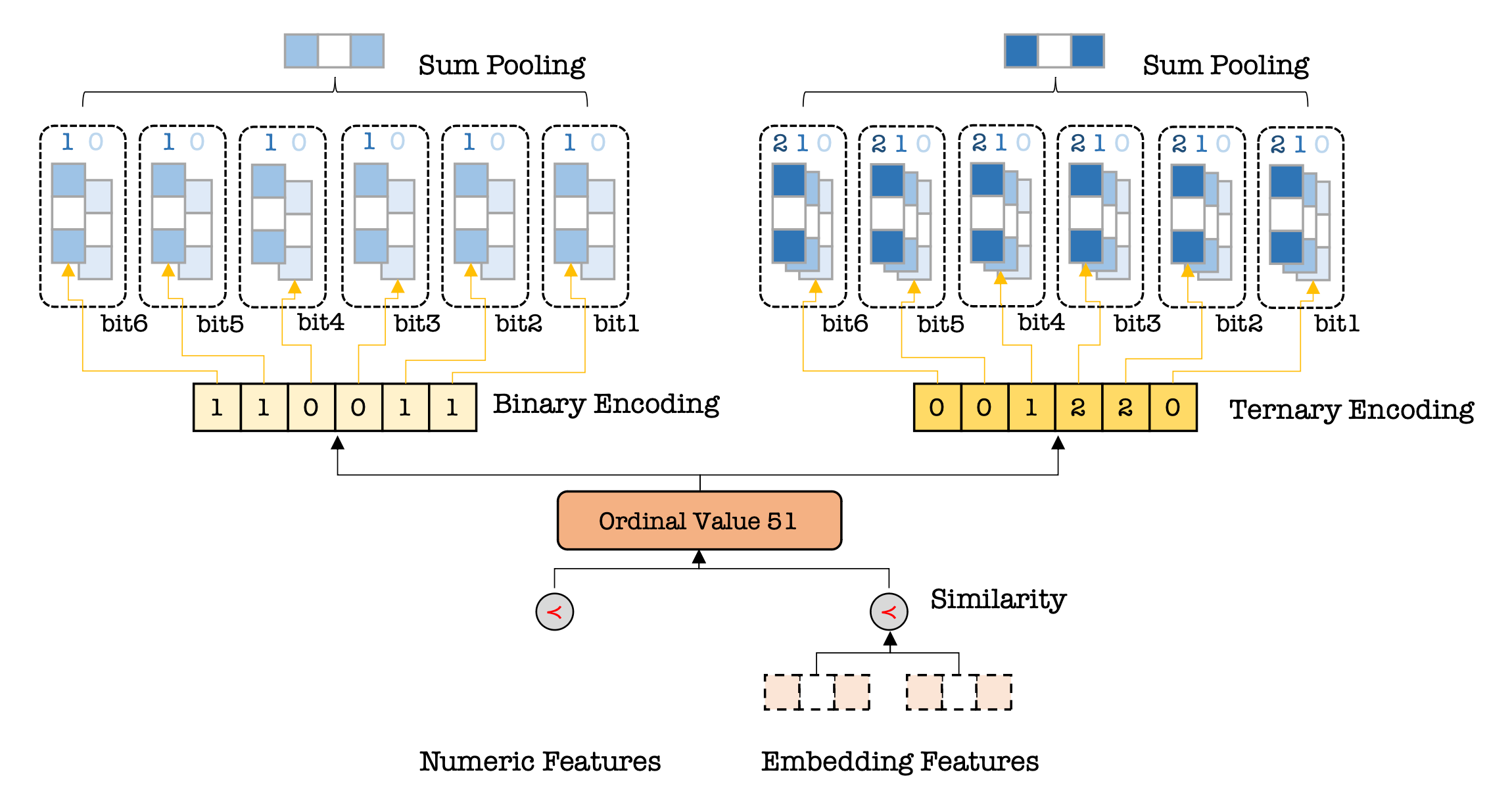
For numeric features such as user age it is preferable to use an encoding that preserves the ordinal information - 51 is closer to 50 than 61, for example, and should be encoded accordingly. Tencent’s model achieves this using an algorithm they call Multiple Numeral Systems Encoding (MNSE).
The key idea is to hash a single number using multiple numeral systems (binary, ternary, decimal, and so on) into multiple codes, and then assign learnable embedding to these codes. Then, using embedding tables we map each of the entries in a code into an embedding, which we sum-pool into one embedding per numeral system. We repeat this step for each numeral system and concatenate the resulting embedding into a single feature to be passed into the ranking model.
For example, “51” may be mapped into the binary code
6_1, 5_1, 4_0, 3_0, 2_1, 1_1,where the first number is the position index and the second number is the binary value. In this system, “50” would be
6_1, 5_1, 4_0, 3_0, 2_1, 1_0,just changing the last of the 6 embeddings. These embeddings are learnable, so the model would end up learning to place the embedding vectors for 1_1 and 1_0 close to each other, while, say, placing the embedding vectors for 5_0 and 5_1 far away from each other (100011 is 35).
Tackling embedding collapse
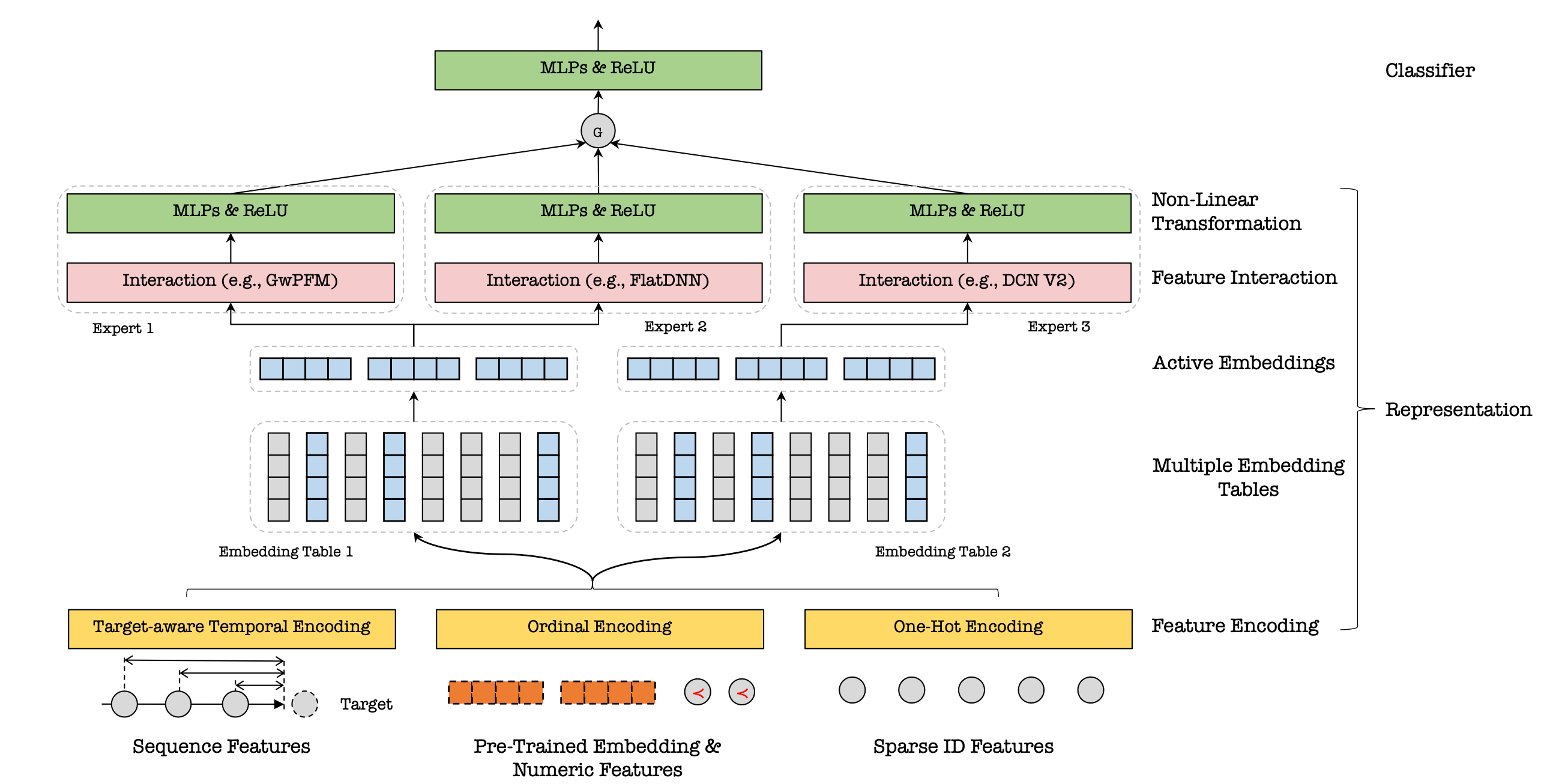
One of the key challenges discussed in the paper is “embedding dimensional collapse”, the observation that the embeddings learned by the model tend to occupy just a small subspace of the available embedding space. This is not only wasteful, it also fundamentally limits how much we can increase the capacity of our model simply by increasing the embedding dimension. The authors argue that the reason for the collapse is the fact that features with low cardinality (such as gender) interact with features with high cardinality (such as user ids) in the interaction arch, “forcing” the high-cardinality features into a smaller embedding space that is favored by the low-cardinality ones.
In order to remedy this collapse, the authors introduce the multi-embedding, heterogenous Mixtures of Experts (MoE) architecture. The key idea is to introduce not one but multiple embedding tables per feature, and then use different embeddings in different interaction modules which are combined with an information gate — this is, of course, the Mixtures of Experts architecture where the experts in this case are the interaction modules.
As a concrete example, Tencent’s Moments ranking model consists of 3 interaction modules, GwPFM, IPNN, and FlatDNN, and two embedding tables. GwPFM and FlatDNN share the first table, while IPNN uses the second one. In this particular example, the authors report that moving from a single embedding to the multi-table design brought a 3.9% GMV lift in, “one of the largest performance lifts during the past decade”.
Tackling interest entanglement
Another of the key challenges discussed in the paper is that of interest entanglement: ranking models typically have dozens of different task heads, each corresponding to different types of user conversion. This can result in negative transfer, where gradients from one task degrade the performance on other tasks.
One way to solve for negative transfer is the multi-gated Mixtures of Experts (MMoE) architecture, where we introduce one gate per task, allowing the model to learn which tasks work well together and share experts accordingly. However, even MMoE-like models are not enough, so authors argue, because they still share the embedding tables across all tasks so that negative transfer can still be introduced.
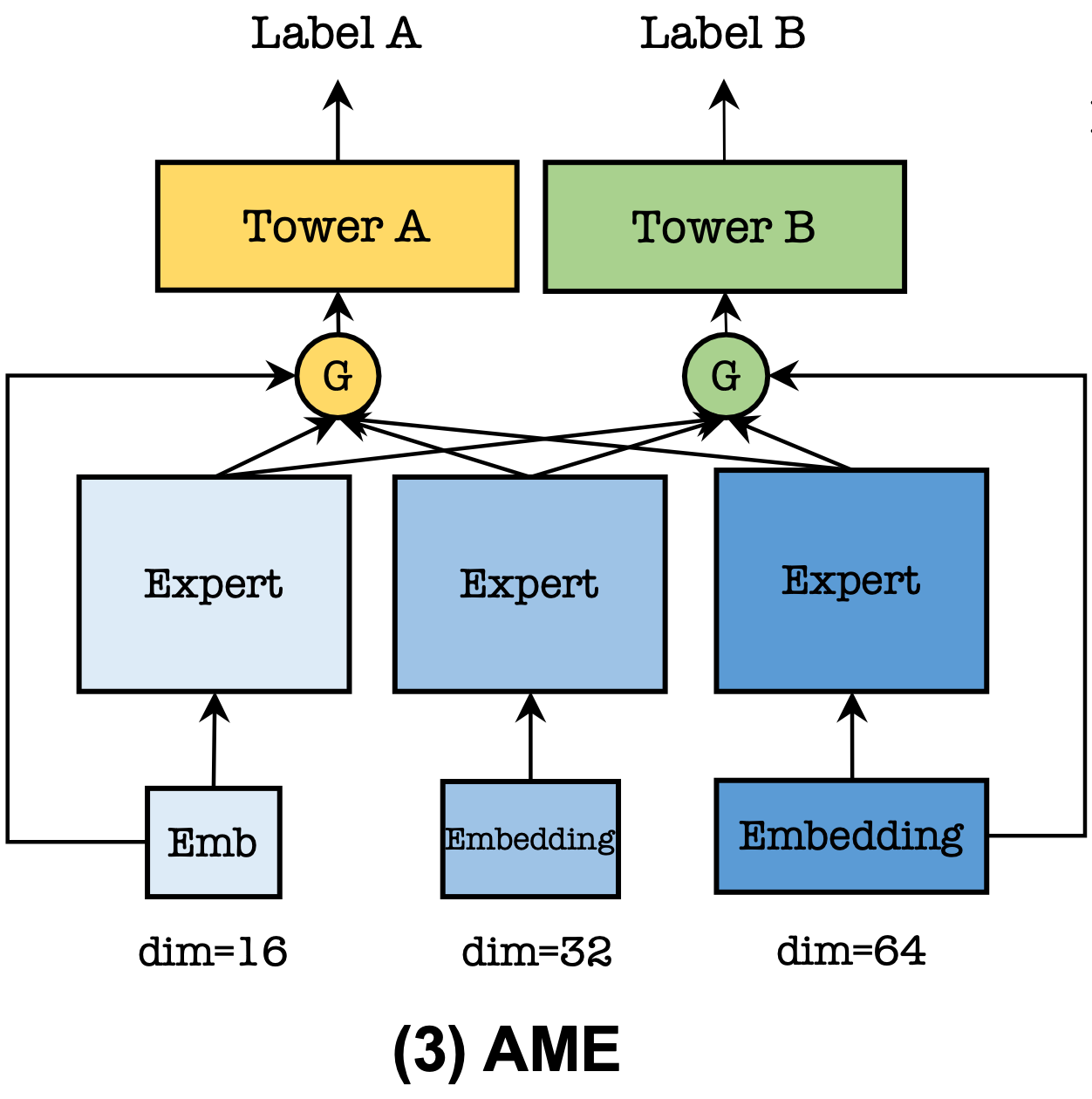
The author’s proposed solution is the so-called “asymmetric multi-embedding” (AME) paradigm, where we not only introduce multiple experts but also multiple embedding tables, one for each expert, and each with its own embedding dimension. The hypothesis behind this approach is that different tasks have different degrees of difficulty to learn and hence require different amounts of modeling capacity. Having access to tables with different embedding dimensions allows the model to allocate more capacity to the more difficult tasks, so the theory.
For example, Tencent’s conversion prediction model learns 100 different conversion tasks using 3 experts with 3 different embeddings tables of dimension 16, 32, and 64. Compared to PLE (an advanced version of MMoE), the authors measure and improvement in conversion prediction of 0.32% - 0.48% AUC, depending on the ranking surface.
Summary
Tencent’s paper offers a number of practical solutions deployed in their ads ranking models, giving us a rare insight into a large-scale industrial recommender system. Key elements of their system are:
Sequence Feature Encoding (TIM): The Temporal Interest Module (TIM) encodes both semantic (similarity between items) and temporal correlations (recency of user interactions) in the user’s history. By pooling target-aware representations of past items, TIM boosts the relevance of recommendations. This led to a 1.93% increase in Gross Merchandise Value (GMV) for WeChat ads.
Numeric Feature Encoding (MNSE): The Multiple Numeral Systems Encoding (MNSE) method transforms numeric values (e.g., age) into multiple numeral systems (binary, ternary, decimal), then maps each system into learnable embeddings. This helps the model preserve ordinal relationships, ensuring that values like “51” and “50” are encoded as being close together in the embedding space.
Tackling Embedding Collapse: To prevent embedding dimensional collapse, where embeddings occupy a smaller subspace than intended, Tencent uses a multi-embedding heterogenous Mixtures of Experts (MoE) architecture. This approach assigns multiple embedding tables to each feature, which are used by different interaction modules. By decoupling feature interactions in this way, Tencent achieved a 3.9% GMV increase in the Moments ranking model.
Addressing Interest Entanglement: The Asymmetric Multi-Embedding (AME) paradigm combats the issue of interest entanglement in multi-task learning. It introduces multiple embedding tables of different dimensions, allowing each task (e.g., click prediction, conversion prediction) to use an appropriate amount of model capacity. By doing so, AME improves prediction accuracy and reduces negative transfer across tasks, with up to 0.48% lift in AUC for conversion predictions.
To summarize, Tencent bets heavily on having multiple embedding tables instead of just a single embedding table per feature, a pattern we’ve seen in their numeric encoding, in their heterogeneous MoE architecture, and in AME. The other interesting observation is that, just like TWIN, Tencent largely leverages target attention to summarize user action histories, which goes against the recent trend of LLM-ifying recommender systems.
It will be interesting to see the next papers coming from this group, which I would expect to dive deeper into the various pieces of their system such TIM. Happy learning!
"Tencent largely leverages target attention to summarize user action histories, which goes against the recent trend of LLM-ifying recommender systems." are you sure about this? Meta's HSTU paper literally metnioned that target aware is significant. Maybe I don't quite get what do you mean?