
The Problem With the Problem With Popularity Bias
Recommender systems tend to be biased in favor of the most popular items - this is not necessarily a problem


Mitigating popularity bias has emerged as one of the major research directions in recommender systems over the recent years. At a high level, the problem this research is trying to solve is preventing ranking models from over-exploiting the most popular content, which is almost guaranteed to bring engagement irrespective of the particular user preference. This popularity bias leads to less diversity in the recommendations and hence sub-par content overall, so the argument.
For a long time, the narrative has been that we need to somehow mitigate this popularity bias and as a result will have better recommendations overall. However, the recent paper “Popularity Bias Is Not Always Evil: Disentangling Benign and Harmful Bias for Recommendation” (Zhao et al 2021) challenges this view, arguing instead that popularity bias is, as the title suggests, not really the problem. Instead, we need to start asking what exactly we are trying to solve for.
(Spoiler alert: the real problem is conformity, not popularity.)
Let’s take a look at this work, and what it means for building unbiased ranking models.
Popularity = quality + conformity
The premise of the paper is that item popularity really consists of two components,
quality, which is a measure for the overall value of the item (irrespective of user preference), and
conformity, which is the amount of engagement the item generates just due to passive conformity. For example, “click-bait” is a type of content with high conformity but not necessarily high quality.
Most importantly, quality is actually a useful signal for our model, but conformity is not. Consequently, we’d like for our ranking models to take into consideration the former but not the latter (at least not at serving time).
In order to prove that popularity can indeed be useful, the authors measure the correlation between popularity and the average item rating value (for example using Amazon star ratings) and show that this correlation is indeed positive in most cases, as shown in the right plot below:
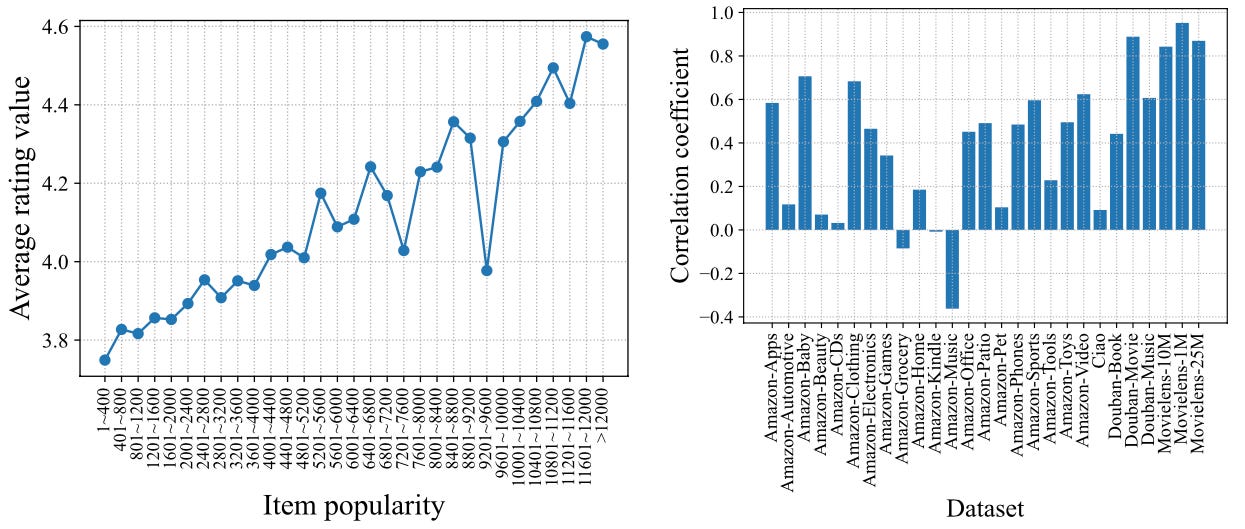
It is interesting to see how much the correlation coefficients vary over different datasets, as we see in the right plot — on some datasets (such as Amazon Music) it’s even negative! This could indicate that some problems are more dominated by conformity effects, resulting in negative correlation, and some are more dominated by quality effects, resulting in positive correlation (assuming, of course, that rating is correlated with quality).
In other words, the amount of correlation may be an indicator of the “passivity” of users, with streaming music being among the most passive, and selecting a movie being among the least passive.
The authors then hypothesize that they can build superior ranking models by explicitly modeling these two terms, quality and conformity, in their ranking model.
The TIDE model: causal view
The authors present TIDE, short for time-aware disentangled framework, a new model architecture designed to do just that. Technically, TIDE is a causal model, that is, a model that makes predictions that are informed by a causal graph. In the problem of recommendations, this causal graph can be drawn as follows:

where
U, I are user and item,
M is the model prediction which can be generated by any form of ranking model (there’s a zoo of them out there, which we’ve covered at length in previous issues, e.g. here).
Q and C are the quality and conformity terms, respectively. t is time.
Y is the prediction, i.e. the probability that user U will engage with item I
C* is an imputed value for the conformity component to be used at serving time. The authors use an imputed value of 0, i.e. no conformity. This imputing is important to make the model unbiased with respect to conformity, but not with respect to item quality.
An important detail is that the time variable t only propagates into the conformity component, not the quality component. This choice is based on the empirical observation that item popularity indeed appears to be decaying somewhat exponentially, as seen in the orange and green curves below. Conformity is strongest if the item is fresh. Over time, the only thing that matters for popularity is quality.

Why would the conformity effect decay over time? One reason is that in the beginning of an item’s life the recommendations are mostly random because we don’t have any engagements yet to learn from. Due to conformity effects, the item will generate engagements and hence appear popular. After some time, once the model has learned the correct audience for the new item, the recommendations will be more targeted and hence generate engagements that are more driven by quality and not just conformity. For items that start out as popular just due to conformity effects, the model will eventually learn that there are no users for targeting.
The TIDE model: algorithmic view
Under the hood, the TIDE model adds a correction term to the model’s output predictions:
where
y is the result from a matrix factorization model for user u and item i,
y-hat is TIDE’s debiased prediction,
q_i is the quality term for item i,
c_i(t) is the time-dependent conformity term for item i.
For c, the authors choose weighted sum of the past interactions where the weights are exponentially decaying, i.e.
where
beta_i is a learnable parameter for each item,
t_l is the time of the item launch,
tau is a free “temperature” parameter that controls how rapidly conformity decays over time,
the sum is taken over all previous engagements of all users with the item.
At inference, the model prediction simplifies to
i.e. we simply zero out the conformity term such as to debias the model.
Results
Tide beats a host of competing algorithms on 3 different click prediction tasks:

The reported improvements over the best competing baseline are particularly impressive on the Amazon dataset, with a ~20% improvement in NDGC. (Note that the authors report relative, not absolute, improvement, perhaps because an absolute improvement of 0.001 looks less impressive.)
The competing algorithms in this chart are:
MF: matrix factorization (without any debiasing),
MF-IPS: matrix factorization with inverse propensity scoring, i.e. re-weighing each instance according to item popularity, a crude way to account for popularity bias that does not take into account the more complex reality including both quality and conformity effects,
DICE, PD, and PDA: competing causal modeling approaches, which, in contrast to this work, do not model the time-dependent conformity effect.
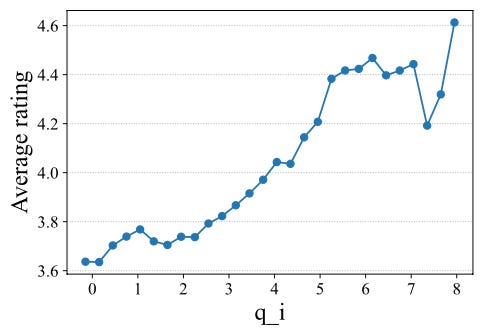
It is also interesting to audit the learned q_i parameters and see how they compare to the actual item rating. Indeed, q correlated with the actual item rating, which confirms that the model indeed learns item quality via the q parameter (assuming, again, that rating is a proxy for quality, which should be true as a first-order approximation but could fail once we take into considerations second-order effects such as review abuse).
Summary
The problem with the problem with popularity bias is that it is not as harmful as it has been traditionally made to be in the literature: item popularity can be an important indicator of item quality, and hence should be considered by the ranking model in making predictions. The real problem is that quality-driven popularity is easily confounded with conformity, i.e. passive user consumption no matter what is being impressed to them. Ideally, we want our models to regard quality but disregard conformity when making a prediction.
The causal TIDE model achieves precisely this, by decomposing item popularity into a fixed quality term and a time-dependent conformity term. Empirically, this model achieves strong performance gains compared to competing causal models (e.g. PD or DICE), such as 20% relative improvement in NDGC on Amazon click predictions.
Unfortunately, the paper does not report online results from running TIDE in a production environment — in fact, the paper does not mention the word “production” even once. I would expect some hurdles in trying to productionize such a system. For example, the c_i(t) calculation is supposed to sum over all previous engagements, which could be prohibitively expensive in very large systems with Millions or even Billions of users. A fair comparison against competing causal models such as DICE should take into consideration not just predictive accuracy but also latency.
References
TIDE: Popularity Bias Is Not Always Evil: Disentangling Benign and Harmful Bias for Recommendation (Zhao et al 2021)
PD, PDA: Causal Intervention for Leveraging Popularity Bias in Recommendation (Zhang et al 2021)
DICE: Disentangling User Interest and Conformity for Recommendation with Causal Embedding (Li et al 2021)
Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in Recommender System (Wei et al 2020)