
Understanding ML Compilers: The Journey From Your Code Into the GPU
How high-level model code is being transformed into low-level machine instructions


Machine Learning frameworks, such as PyTorch, TensorFlow, or JAX, have made model design as simple as never before. These tools abstract away many complexities, allowing developers to focus on building and refining models without worrying about the low-level details of computation. However, the magic that transforms high-level code into efficient execution on GPUs or other accelerators often goes unnoticed.
This transformation is done by ML compilers, the unsung heroes in the machine learning pipeline. ML compilers take your model code and optimize it to maximize performance on specific hardware. They bridge the gap between user-friendly frameworks and the intricate architecture of GPUs, ensuring that operations are executed efficiently, memory usage is optimized, and compute resources are fully leveraged.
In this post, we’ll explore the journey your code takes — from high-level model definition to optimized GPU execution — and shed light on the critical role of ML compilers and Intermediate Representations (IRs) in modern ML workflows. To keep things simple, we will focus on the PyTorch ecosystem, but note that other ML frameworks will have their own variants of the concepts discussed here.
Let’s get started.
PyTorch
It’s a common misconception that PyTorch (Paszke et al 2019) is purely a Python framework. While it’s true that PyTorch provides a Pythonic API for defining neural networks, performing tensor operations, and running training loops, Python is just the frontend. Behind the scenes, much of the heavy lifting happens in the C++ backend.
At the heart of this backend lies ATen ("A Tensor"), PyTorch’s core library for tensor operations. This raises an important question: how does the Python code communicate with the high-performance C++ backend? The answer lies in bindings.
In software engineering, bindings are the bridges that connect one programming language to another. A familiar example is the Cython library, which allows Python code to interface with C/C++ functions. PyTorch uses a specific binding library called PyBind11 (you can confirm this by reading the PyTorch backend code, for example here).
When you execute a Python operation in PyTorch (like torch.matmul()), PyBind11 forwards the Python call to its corresponding C++ implementation in the backend. This seamless connection allows PyTorch to offer a user-friendly Python API while leveraging the speed and efficiency of C++. In essence, PyTorch provides developers with the best of both worlds: the ease of Python and the performance of C++.
CUDA

NVIDIA’s CUDA, short for “Compute Unified Device Architecture” (Ghorpade et al 2012), is a compute architecture specifically designed to take advantage of the GPU’s high degree of parallelism. The fundamental unit of code execution in CUDA is a thread, running a single CUDA operation, or “kernel”. Threads are executed together in blocks, with up to 1,024 threads per block. A Streaming Multiprocessor (SM) is the fundamental hardware component of an NVIDIA GPU, and each SM is responsible for executing a fixed number of blocks that together make up the entire program. For example, NVIDIA’s H100 GPUs has 168 SMs, each of which can handle 2,048 threads in parallel, resulting in a theoretical maximum of 344,064 active threads running at the same time.
CUDA C++ is an extension of C++ specifically designed for NVIDIA GPUs and their CUDA architectures. The main functionalities added by CUDA that are not inherent to C++ itself are the following:
Keywords for specific GPU functions:
__global__: Used to define a function (kernel) that will be executed on the GPU and can be called from the host (CPU).__device__: Used to define a function that will only be executed on the GPU and can only be called from other GPU code.__host__: Used to specify that a function will run on the CPU (this is the default for regular C++ functions).
Parallel Execution Model:
CUDA C++ introduces the concept of threads, blocks, and grids to manage how computations are distributed across the GPU.
You specify how many threads and blocks to use when launching a kernel, allowing you to take full advantage of the GPU's parallelism.
Memory Management:
CUDA provides APIs for allocating and managing memory on the GPU, as well as transferring data between the CPU and GPU.
Functions like
cudaMalloc(),cudaMemcpy(), andcudaFree()are used to manage memory in CUDA.
For example, here is a simple CUDA program that computes the sum of two integers on the GPU, copies the result to the CPU and prints it:

Here,
The
__global__keyword indicates that theaddfunction is a CUDA function that will run on the GPU. In technical terms,addis a particular CUDA kernel.The
add<<<1, 1>>>(a, b, d_result)launches the CUDA kernel with 1 block consisting of 1 thread.GPU memory is allocated using
cudaMallocand deallocated usingcudaMemcpy. We usecudaMemcpyto copy the result from the GPU to the CPU, where we can print it out.
NVCC: NVIDIA CUDA Compiler
So far we’ve learned that PyTorch gives you the luxury of being able to write your model architecture in Python code while translating the code into C++ / CUDA C++ under the hood using bindings. GPUs however do not operate directly using C++ instructions, but have an instruction language called Streaming Assembler (SASS), representing the final set of instructions that the GPU executes. These instructions are optimized for the specific GPU microarchitecture (V100, A100, H100, etc). Since SASS is close to the hardware, it provides a precise representation of how the GPU will execute operations.
SASS code is rarely written manually due to its complexity. Modern GPUs have thousands of cores and complex memory hierarchies, making manual optimization infeasible for most people. To get a sense of the complexity, here is an extremely simplified piece of SASS code for manipulating the memory across 3 memory registers (the fundamental units of storage directly on the GPU):

In order to translate our C++ code into machine (SASS) code, we need a compiler, and in the context of the NVIDIA ecosystem the most commonly used compiler is NVCC, short for NVIDIA CUDA Compiler (although there are other compilers as well). At a high level, the steps performed during the NVCC compilation process are as follows:
Preprocessing: The CUDA C++ code is preprocessed and split into host (CPU) and device (GPU) code. Preprocessing involves several actions that prepare the code for compilation, including inserting the includes in the beginning of the code, expanding macros, removing commented out lines, and so on.
Host Code Compilation: The CPU code is compiled with a standard C++ compiler.
Device Code Compilation: The GPU code is compiled into PTX (“Parallel Thread Execution”, an intermediate language in between C++ and SASS) and then into device-specific SASS, which is packaged into a CUBIN (“CUDA binary”) file.
Linking: The CPU and GPU code are linked together to form the final executable.
Execution: The executable runs on the CPU, which manages and launches the GPU kernels using the CUBIN file.
PTX: Parallel Thread Execution
PTX (NVIDIA 2009) is an assembly-like language that represents parallel computing instructions for NVIDIA GPUs. It is not executed directly by the GPU hardware but is used as an intermediate step in the compilation process. We call this an Intermediate Representation (IR) of the code. One of the motivations behind PTX in particular and IRs in general is to have an abstraction on top of SASS that allows for some level of portability across different generations of NVIDIA GPUs without having to re-compile from scratch.
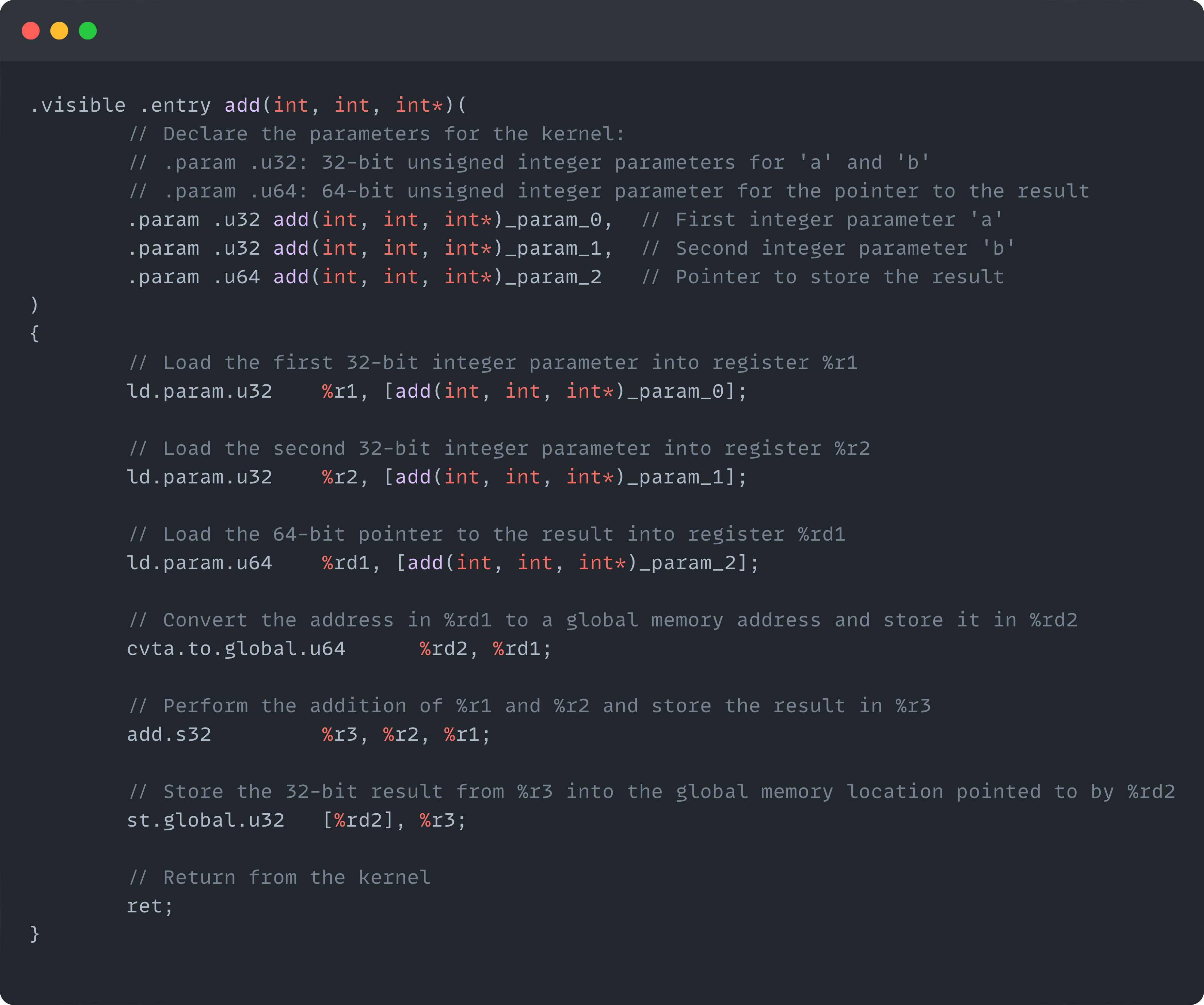
Here for example is the PTX code corresponding to the CUDA “add” kernel we defined earlier (which I generated using Compiler Explorer with NVCC 12.4.1):
There are two different paradigms for converting PTX into SASS, AOT and JIT:
AOT (“ahead of time”) means that the conversion happens at NVCC compile time, so NVCC is compiling all the way from C++ to SASS. Of course, this only works when we specify the hardware type (e.g. A100, V100, H100, or something else) at compile time.
JIT (“just in time”) means that PTX is compiled into SASS at runtime by the NVIDIA Driver, depending on the hardware present. This allows the same PTX code to be used on different GPUs, with the NVIDIA driver optimizing for the specific architecture.
Ahead-of-Time (AOT) compilation offers better performance since the code is fully compiled before execution, but it sacrifices flexibility. This makes AOT a preferred choice in environments where consistent performance is critical, such as high-performance computing research. In contrast, Just-In-Time (JIT) compilation is more commonly used in scenarios where flexibility is key, such as cloud deployments with unpredictable device availability.
For ML models, JIT provides a significant advantage: it eliminates the need to compile the entire model ahead of time. This allows for faster iteration and experimentation, making it ideal for dynamic and evolving workflows.
FX: Functional Transformations
Torch FX (“Functional Transformations”) is a tool within the PyTorch ecosystem for capturing, transforming, and optimizing the graph of a neural network prior to NVCC compilation. Technically, FX is not a compiler, but an IR, similar to PTX. Unlike PTX though, the focus in FX is on Pythonic graph transformations that are closer to the abstraction level of the model itself.
Under the hood, FX uses a technique called symbolic tracing, which involves running the model with sample inputs and recording the sequence of operations performed on the input. The result of this symbolic trace is a graph that represents the flow of computations in the model. This can be particularly useful for very complex models because the symbolic tracing process would get rid of any redundancies in the model. For example, if certain modules are defined inside the model code but never used, by definition they will also not show up inside the symbolic trace.
In PyTorch, we can simply compute the symbolic trace of our model using the torch.fx API as follows:

One of the challenges with using FX is that not all PyTorch code is automatically FX-traceable. In order for the symbolic tracing algorithm to succeed, certain criteria must be met by the code:
Use of standard PyTorch operations: symbolic tracing can only trace through standard PyTorch functions and modules. If a model uses custom Python code, the symbolic trace operation would fail. A work-around is FX’s wrap decorator, which can be used to mark non-PyTorch code as a “leaf node” in the computational graph, hence excluding it from the trace.
No Data-Dependent Control Flow: the control flow of your model (if statements or for loops) must be independent of the input data. For example, if the behavior of an if statement depends on the value of the input tensor, FX symbolic tracing will fail.
Input tensor shapes must be compatible: the sample inputs used for symbolic tracing must be representative of the inputs your model will receive during inference. Symbolic tracing uses these inputs to generate the computation graph, so using incorrect or atypical inputs may lead to incorrect graphs.
Even though FX is not strictly necessary, it has become a valuable tool for latency optimization, especially for very large and complex models. For example, Reed et al 2022 report a 6% improvement in latency when training a ResNet50 model on V100 GPUs.
Outlook
Machine Learning compilers are an indispensable part of modern AI workflows, bridging the gap between high-level frameworks and the increasingly diverse range of hardware platforms. One of the most promising research directions in this domain is the development of novel IRs, such as Google's MLIR, Apache’s Relay, Microsoft's DistIR, or OpenAI’s Triton. A common theme across these works is a growing focus on optimizing computation graphs and enabling portability across hardware.
Another interesting research direction is the use of LLMs to write and optimize low-level code directly, thus enhancing or even replacing a traditional compiler. Notable examples are Nova (Jiang et al 2023), a generative LLM designed for writing assembly code, and LLM Compiler (Cummins et al 2024), a suite of pre-trained models based on Code Llama specifically designed for code optimization tasks. The idea of AI systems compiling and optimizing their own code may seem like science fiction, but emerging tools are making this a plausible reality.
CUDA has long been a dominant force in ML due to its tight integration with NVIDIA GPUs and a rich ecosystem of libraries. However, a question lingers: is CUDA the optimal architecture for AI, or simply a “local minimum” in a much more vast landscape of architectural design choices? Viewed in this context, it is interesting to see the emergence of competing paradigms such as AMD’s ROCm, Google’s TPUs, Graphcore’s IPUs, and others.
As the field progresses, the integration of intuitive ML frontends, flexible IRs, and efficient hardware accelerators will shape the next generation of ML systems. The key in “full-stack” ML engineering will be to achieve a good balance between adaptability and performance, creating a cohesive stack where every layer — from model architecture design to hardware execution — works seamlessly to deliver optimal results.