
LLM Evaluation: The New Bottleneck in AI
Language models are improving faster than we can reliably measure them — and that’s becoming a problem.


It is 2026, and LLM-generated content is everywhere, from brainstorming with ChatGPT to web search with Gemini, personal note editing with Notion AI, and code generation with Claude.
The question is no longer “how do we build LLMs that can generate convincing text?” but rather how to evaluate them in a way that actually makes sense. Traditional benchmarks such as GLUE, SuperGLUE, MMLU, BigBench, SQuAD, Natural Questions, HellaSwag and their variants struggle when the domain is as open-ended as a chatbot.
This raises a fundamental research question:
How do we evaluate systems designed to answer essentially any question?
This week, we’ll look at three pivotal works that shaped the modern landscape of LLM evaluation:
HELM — which introduced the idea of holistic LLM evaluation, exposing trade-offs that remain hidden when using traditional benchmarks.
Chatbot Arena — which demonstrated that crowdsourced human judgments can evaluate LLMs “in the wild.”
LLM-as-a-Judge — which showed that LLMs themselves can approximate human evaluation, albeit with important caveats.
Let’s take a look.
HELM (Stanford University, 2023)
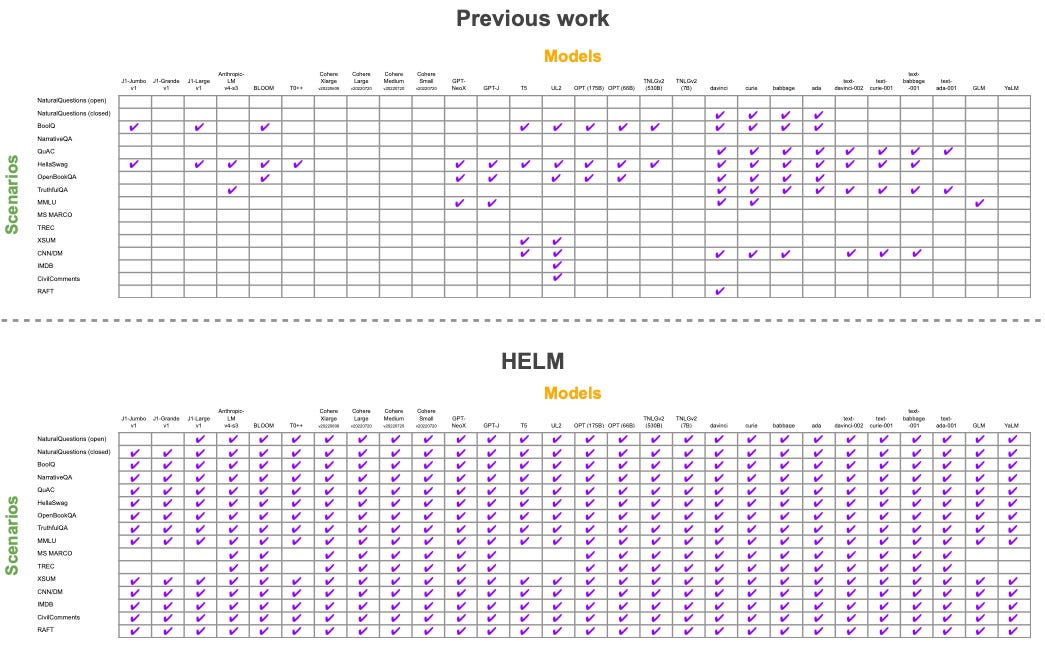
The authors of HELM (Holistic Evaluation of Language Models) argue that previous work on LLM benchmarking has focused too narrowly on single metrics that can be easily optimized, sometimes simply through memorization of particular benchmark datasets. They claim that to truly understand LLM behavior, evaluation must span multiple metrics across multiple tasks, surfacing not just a single performance indicator but a broader set of trade-offs.
Concretely, the authors introduce 16 LLM “scenarios” represented by established benchmark datasets such as Natural Questions, MS MARCO, IMDb, and others. Across these scenarios, they measure 7 evaluation metrics:
accuracy — how well the model predicts the correct labels
calibration — how well the model estimates the uncertainty of its own answers
robustness — how stable model outputs are under small input perturbations such as rewording or typos
fairness, bias, and toxicity — measured using specialized classifiers designed for each of these dimensions
efficiency — the model’s latency and throughput characteristics
These seven desiderata allow for a richer analysis of model behavior beyond raw accuracy. A model may achieve high accuracy while still producing toxic or unfair outputs — trade-offs that may be unacceptable depending on the application.
Armed with the HELM framework, the authors then benchmark 30 language models, including state-of-the-art systems at the time from Anthropic (Anthropic-LM), Google (UL2), OpenAI (davinci), and others. All models are evaluated across the same 16 scenarios using the same 7 metrics, resulting in a total of 17 million queries, 12 billion tokens, $38k in API costs for commercial models, and roughly 20,000 GPU hours to run open-source models locally — a thorough but expensive experiment.
The effort paid off. The resulting paper spans 165 pages and reports 25 high-level findings, including:
Instruction fine-tuning provides broad advantages. The only two instruction-tuned models in the benchmark both rank in the top three on accuracy, robustness, and fairness, with OpenAI’s davinci ranking #1 on all three.
Accuracy, robustness, and fairness are correlated. Models that are more accurate also tend to be more robust and fair.
Accuracy and calibration are largely uncorrelated. A model that predicts the correct answer is not necessarily good at estimating its own uncertainty.
Accuracy does not predict bias or toxicity. A model may be highly accurate while still producing biased or toxic outputs.
Perhaps most importantly, the HELM study showed that there is no single “best” model across all seven desiderata. Different models optimize for different qualities. OpenAI’s davinci, for example, leads on accuracy, fairness, and robustness, but not on toxicity. The least toxic model in the study was T0pp, released by BigScience, a collaboration led by Hugging Face.
All this points to a simple conclusion: a single metric is not enough. Model quality is inherently multi-dimensional, and our evaluation methods should reflect that.
Chatbot Arena
Like HELM, the creators of Chatbot Arena (Chiang et al, 2024) criticize static LLM benchmarks for failing to reflect real-world usage, which is far more open-ended and diverse than fixed evaluation datasets. However, unlike HELM, their solution is not to introduce additional metrics and datasets, but instead to leverage human preference judgments directly.
Chatbot Arena is a live benchmark that is powered by (volunteer) crowd-sourcing. Its creators make the latest and most capable LLMs available free of charge in a simple web UI. Users submit questions, see two answers from two different SOTA LLMs, and rate which answer is preferred, if any, using four buttons at the bottom of the UI (“👈 A is better”, “👉 B is better”, “🤝 Tie”, and “👎 both are bad”).
Under the hood, the outcomes of these battles are fit to a Bradley–Terry model, which models the probability that model m beats model m′ as
where the coefficient ξm represents the overall strength of model m. From these learned coefficients, the rank of model m can then be computed using standard competition ranking,
which simply counts how many models are stronger than model m. As a concrete example, suppose we have four models with coefficients
GPT-4: ξ = 2.0,
Claude: ξ = 1.8,
Gemini: ξ = 1.8,
Llama: ξ = 1.2,
then we’d rank GPT-4 as #1, Claude and Gemini as #2, and Llama as #4.
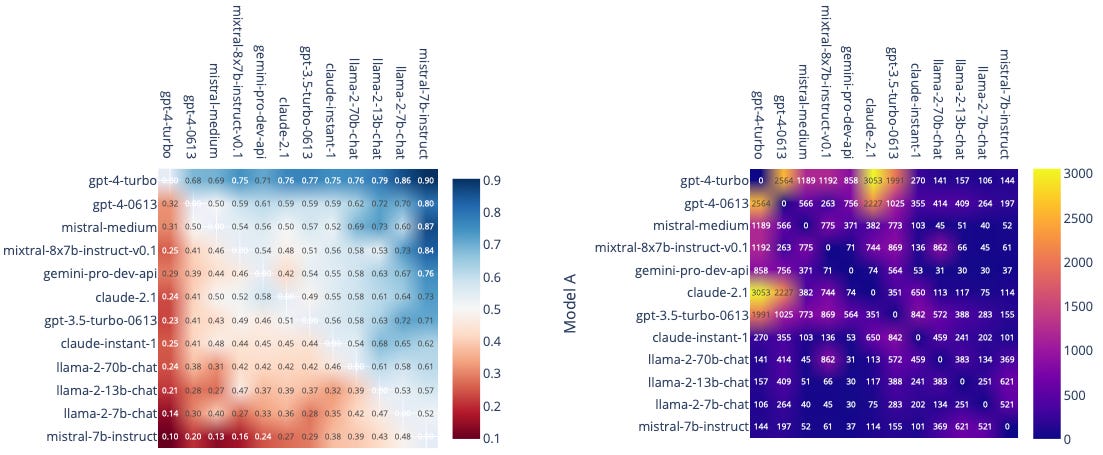
One interesting technical detail is that models are paired based on maximum uncertainty in the battle outcome — that is, matchups where the estimated win probability P is closest to 0.5. Over time, this adaptive sampling strategy causes strong models to be matched increasingly often against other strong models, as reflected in the heatmap above (which is hottest for ChatGPT-4-Turbo vs Claude-2.1).
To validate the judgments of the crowd volunteers, the authors conducted a controlled experiment in which two expert judges — graduate students from UC Berkeley — re-rated 160 crowd battles between GPT-4 and Llama-2. They measured an agreement rate between experts and crowd volunteers of 73–78%, which is reasonably close to the agreement rate between the two experts themselves (~90%), lending support to the reliability of the crowd-based approach.
Chatbot Arena proved to be a huge success. In its first year after launch, it collected 240k votes from 90k users across more than 100 languages, comparing over 50 state-of-the-art LLMs. Today it remains one of the most influential LLM evaluation platforms, and new models are often taken seriously only after performing well on the Arena leaderboard.
LLM-as-a-Judge

LLM-as-a-judge, first introduced in Zheng et al, 2023 (the same authors behind Chatbot Arena), is perhaps the hottest new area in LLM evaluation right now. The idea of using LLMs to judge other LLMs is still emerging. It can work — but it must be carefully validated, and there are important caveats and limitations to consider.
More concretely, several systematic biases have been observed when LLMs act as preference judges:
Position bias — in side-by-side comparisons, LLMs tend to favor the first response shown.
Verbosity bias — LLM judges often prefer longer responses, even when they are less useful.
Self-enhancement bias — LLMs tend to favor responses generated by their own model family. A Gemini judge, for example, will tend to prefer Gemini-generated answers.
Limited reasoning bias — LLMs can make evaluation mistakes on problems they could solve themselves. GPT-4, for instance, has been shown to misjudge answers to relatively simple math questions.
Some of these issues can be mitigated with practical techniques. For example, responses can be presented in both orders, accepting the LLM’s judgment only if it is consistent across permutations to counteract position bias. Another trick is to have the LLM judge first answer the question itself, which helps reduce errors stemming from limited reasoning.
These techniques improve reliability, but LLM judges still need to be validated through controlled studies. In the paper, the authors conduct such a study using MT-Bench, a dataset of 80 high-quality multi-turn questions spanning eight categories: writing, role-play, extraction, reasoning, math, coding, STEM, and humanities & social science.
These questions are answered by six LLMs — GPT-4, GPT-3.5, Claude-v1, Vicuna-13B, Alpaca-13B, and LLaMA-13B — and the responses are evaluated by 58 human experts in side-by-side preference comparisons, effectively creating a smaller, controlled version of Chatbot Arena.
The authors then compare agreement rates between the human experts and three different LLM judges — GPT-4, GPT-3.5, and Claude-v1. They find that the GPT-4 judge achieves the highest agreement with human evaluations at 85%, compared with 82% agreement between human annotators themselves. In other words, on average, humans agree slightly more with the GPT-4 judge than they do with one another, providing strong statistical evidence that LLM-as-a-judge can indeed approximate human preference judgments.
Outlook
As LLMs become increasingly embedded in our day-to-day lives, evaluation will only grow in importance. LLM-as-a-judge currently appears to be the most promising path for scaling evaluation, but the problem is far from solved. We still have limited understanding of the biases that may exist in LLM judges and how to reliably mitigate them. Work such as Zheng et al points in the right direction, but substantially more research is needed in this area.
Another notable risk is the “rubber-stamp effect” (Dietz et al, 2025). When humans are asked to verify whether an LLM response makes sense, they are significantly more likely to agree with the model’s assessment—even when it is demonstrably incorrect. This phenomenon resembles the Ash conformity effect from psychology. As a result, human verification of LLM-generated labels, including preference judgments, can degenerate into passive agreement if not designed carefully. In the worst case, this creates a feedback loop in which human-validated outputs still converge toward the model’s own preferences.
For now, getting LLM evaluation right still requires either comprehensive offline benchmarks (like HELM) or large-scale human preference data (like Chatbot Arena). Fully automated evaluation may eventually become viable, but in 2026, human judgment remains an essential part of the loop.