

Towards Life-Long User History Modeling in Recommender Systems
Towards Life-Long User History Modeling in Recommender Systems
User histories are by far the most important inputs to ranking models but have historically been truncated to curb computational costs. New research changes that.


User action sequences are the most powerful inputs in recommender systems: your next click, read, watch, play, or purchase is likely related to what you’ve clicked on, read, watched, played, or purchased in the past.
A very effective way to model these sequences in ranking models is target attention — pioneered in Alibaba’s 2018 Deep Interest Network (DIN) — where we use attention scores between the candidate and the items in the user history sequence as weights when pooling the sequence into a single embedding:
where t is the embedding of the target item for which we predict probability of engagement, and u (consisting of u0, u1, …) are the embeddings of items in the user action sequence.
(You may be wondering about the missing softmax operation in the equation above — indeed, not all implementations include it. For example, in the DIN paper the authors deliberately exclude the softmax such as to preserve the intensity information about the input signals.)
However, DIN’s target attention scales like
TA ~ O(LxBxD),where
L is the length of user sequences,
B is the number of items we rank in a single request to the model, and
D is the embedding dimension,
which introduces a computational bottleneck, especially so if both L and B get very large: long histories and large batch sizes mean that we have to compute lots (BxL) of dot products, all of which require D compute operations. In practice, this bottleneck limits the length of histories that we can model, preventing us from building “life-long” user history models that consider the entire history of their users.
An interesting research domain that has emerged over the past years is therefore the question of how to approximate the target-attention computation and thus unblock these life-long models. Let’s take a look.
SIM (Alibaba, 2020)
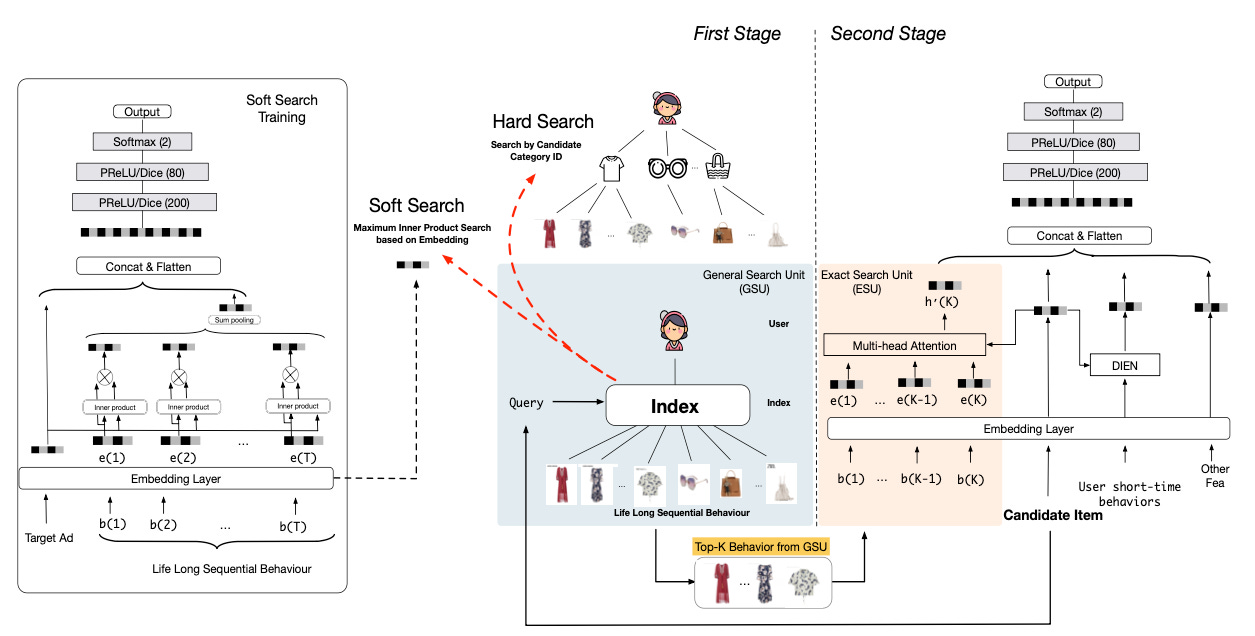
The key idea in Alibaba’s Search-based Interest Modeling (SIM) algorithm is to approximate E(t,u) as
where we sum only over those items S in the user action sequence that we expect to be most similar to the target, based on heuristics. The key hypothesis here is that the most similar items will have the largest target attention scores, and therefore E-tilde will be closer to E compared to, say, randomly sampling items from u.
Thus, we can get a reasonable approximation for E with much fewer attention computations, as determined by the cardinality of S, which we’ll denote as k:
SIM ~ O(kxBxD),which is L/k times cheaper than standard target attention, e.g. 100 times cheaper if L=10K and k=100.
The crux then lies in having an efficient method for determining the items in S, i.e. those items we expect to be most relevant given the target. The authors consider two different heuristics to do that, namely “hard search” and “soft search”:
In hard search, we keep only those items in u that have the same category as t. For example, in e-commerce recs, if the target category is “handbag”, we’d only keep those items in the user history that are also handbags and pass those into the target attention algorithm.
In soft search, we train a separate neural network to learn small embeddings for items, and then apply maximum inner product search (MIPS) to find the top-k items in u that are most similar to t.
You may be wondering why we’re gaining anything from soft search because we are replacing dot products in the original attention scoring with dot products in MIPS, i.e. we still have to do dot products! The first trick is that the new embeddings in soft search can have lower dimension than the original embeddings, thus speeding up MIPS. The second trick is that MIPS can be solved with sub-linear computational complexity using the ALSH (asymmetric locality-sensitive hashing) algorithm, which uses hashing to approximate the dot products.
The authors compare both SIM implementations to DIN on production data from Alibaba which includes 300M users, 600M items, 100k categories, 12B engagements, and sequence lengths of up to 54,000 items. Compared to DIN (which only considers the most recent items, i.e. not the entire history), both soft and hard SIM achieve around 2.3% better AUC on the production data, which proves the effectiveness of leveraging long-term user histories. Hard search was deployed into production due to its simplicity and smaller computational footprint compared to soft search.
ETA (Alibaba, 2021)
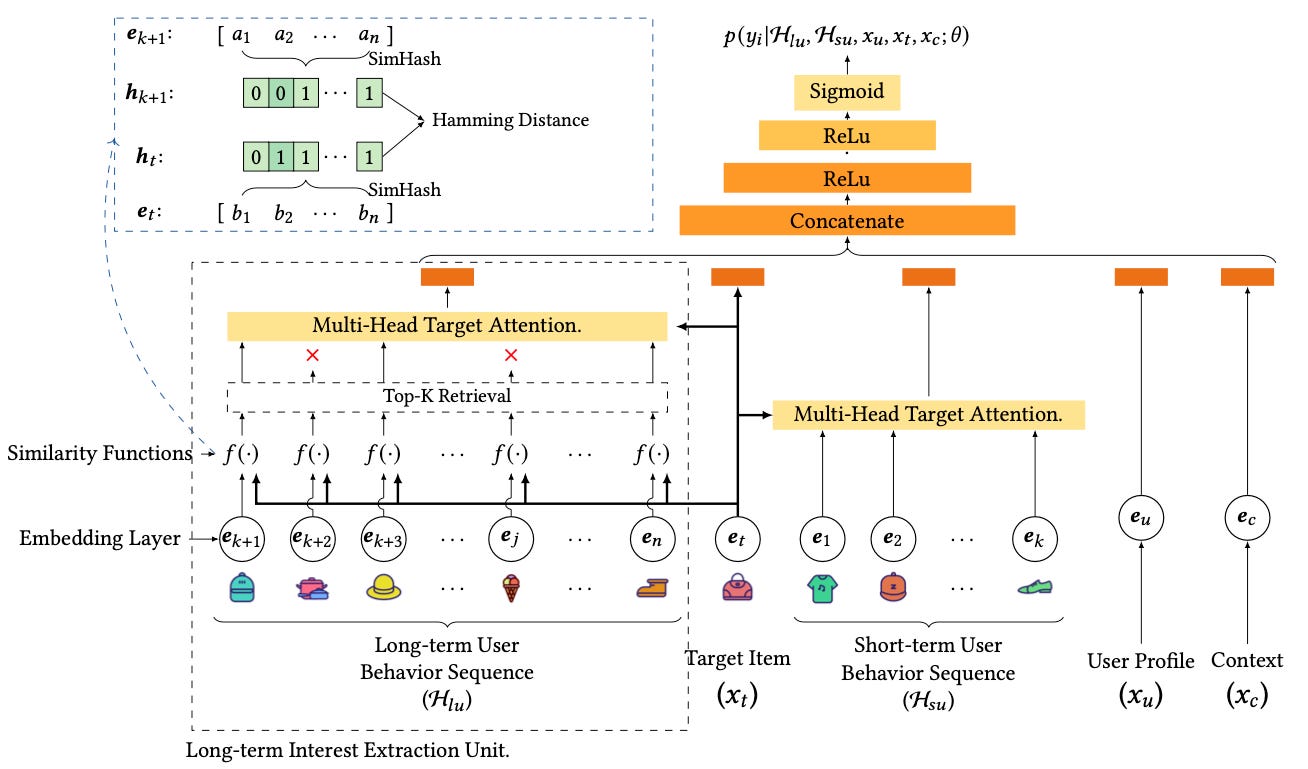
Like SIM, ETA (End-to-end Target Attention, also from Alibaba) solves target attention in two stages, where the first stage retrieves the items in the history that are most relevant to the target and the second stage computes the attention pooling. However, unlike SIM, ETA’s retrieval stage estimates the top k most relevant items in the user sequence using Hamming distances of their binary hash signatures, retrieving the k items that have the smallest Hamming distances with respect to the target.
The m-dimensional hash signatures are computed using SimHash, which computes the dot product between the item and m fixed, random vectors, and maps these dot products into a binary code by applying the Heaviside function (which maps negatives to 0 and positives to 1). Formally,
where R_i are random embeddings and f is the Heaviside step function. The motivation behind this hashing approach is that it is locality-sensitive, which means that embedding vectors that are similar are more likely to have identical hash signatures: if two vectors are similar to each other, then they will also have similar dot products with respect to any random, third vector.
The beauty about ETA is that Hamming distance of binary inputs scales as O(1) with respect to the input size because it can be computed with a single XOR operation, followed by simply counting the number of “1” bits. Thus, once we have computed the hash signatures, we can solve target attention with
ETA ~ O(LxBx1) + O(kxBxd)where the two terms correspond to the top-k retrieval and attention pooling operations, respectively.
Note however that, unlike SIM, computing the hash signatures themselves also adds computation that scales like
hashing ~ O( (B+L)xdxm )because we have to compute the dot products of each d-dimensional candidate item as well as each d-dimensional item in the user history with each of the m random vectors. Thus, ETA may not be favorable if m is very large: in fact, in the paper the authors consider only very small signatures with m=4, i.e. only 4 bits!
The remarkable result is that even with such a small hash signature, ETA is still able to beat hard SIM by 0.5% AUC on a recommendation problem dataset from Taobao and achieve comparable inference latency. This result indicates that, at least at the retrieval stage of target attention, we can get away with extremely crude approximations, as long as we still run the full target attention computation on the retrieved items.
SDIM (Meituan, 2022)
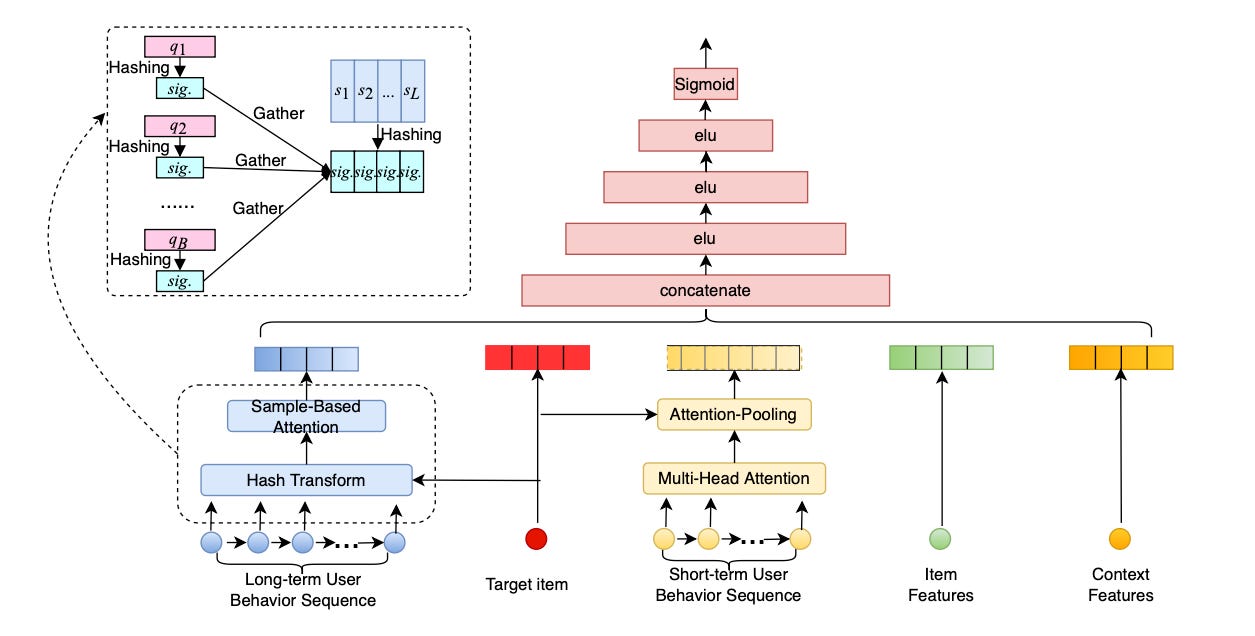
Like ETA, Meituan’s SDIM (“Sampling-based Deep Interest Modeling”, Cao et al 2022) computes hash signatures for both target item as well as the items in the user action sequence. However, unlike ETA, we don’t compute Hamming distances but instead use hash collision as a proxy for relevance: if the item in the user history has exactly the same hash signature as the target, we keep it, otherwise we don’t. Then, we simply pool the embedding of all items in the history that are left, using the size of the hash signature to control the size of the filtered sequences: the longer the hash signature, the less likely the collisions, and hence the smaller the filtered sequences.
You may be wondering how we take into account random collisions, i.e. items colliding that are not actually similar but just colliding randomly. The trick is to hash multiple times (each time with a new random seed) and then average out the effect of random collisions, a trick also known as multi-round hashing.
Thus, the computational complexity of target attention in SDIM is
SDIM ~ O( (L+B)xmxd )which comes just from computing the m-dimensional hash signatures for the B target items and L history items. This can be further reduced to
SDIM ~ O( (L+B)xmxlog(d) )using yet another ML trick, the Approximating Random Projection algorithm (Andoni et al 2015), which reduces the computational complexity of random projections from d to log(d) — you’ve guessed it — using hashing.
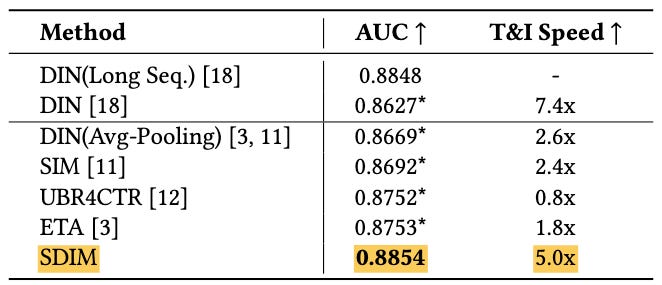
In experiment on production data, SDIM beats ETA by 1% AUC while at the same time being 5X faster in both training and inference, a remarkable result! It also beats SIM and, of course, DIN.
Summary
Target attention, as pioneered in DIN, is an extremely effective way to featurize user histories such as to maximize predictive accuracy with respect to the target item we need to rank. However, target attention scales with O(LxBxd) (user history x batch size x embedding dimension), which does not scale well. Here, we’ve seen 3 approaches to get around this compute bottleneck:
SIM, which breaks down target attention into a retrieval stage and a pooling stage. Retrieval can be solved with either hard search, which keeps only items from the same category as the target, or soft search, which keeps the k closest items in an embedding space.
ETA, which creates binary hash signatures for all items and uses Hamming distance as a proxy for relevance: the smaller the Hamming distance, the more relevant the item. The trick is to use a hashing algorithm that is locality-sensitive, such that similar vectors end up with similar hash signatures. ETA uses SimHash.
SDIM, which follows the hashing idea from ETA but get rids of the Hamming distances and instead uses hash collision directly as a proxy for retrieval relevance, that is, we simply retrieve all items from the user history that collide with the target in hash space.
As recommender systems become more deeply intertwined with society, life-long algorithms —models that can be target-aware with respect to entire user histories— will become ever more important. This is a hugely important research domain, and I would bet to see increased innovation in this space in the coming years. Watch this space.
💪 Get 30% off my e-book Machine Learning on the Ground using the discount code MLFRONTIERS.