

Deep Hash Embedding: Solving Recommender Systems' Memory Bottleneck
Deep Hash Embedding: Solving Recommender Systems' Memory Bottleneck
Embedding tables make up the vast majority of parameters in neural recommenders - a new feature encoding paradigm may change that.


Embedding tables — look-up tables that map sparse id features to low-dimensional, dense vectors — are one of the core components of modern recommender systems.
The underlying algorithm is simple: we first hash the id into a one-hot hash vector, and then map this vector into a low-dimensional, dense embedding vector using a fully connected layer. At serving time, this fully connected layer can then be used as a look-up table i.e. the embedding table for that particular id. In a typical recommender system, we’d have multiple such embedding tables, corresponding to user id, item id, the list of items the user engaged with in the past, and so on.
By design, embedding tables are memory-hungry, such that the vast majority of parameters in a modern recommendation model are stored in its embedding tables. For example, a single sparse feature with a hash size of 100M and an embedding dimension of 128 with 32bit precision would already consume 50GB of memory, already exceeding the entire memory of an Nvidia V100 GPU. Add more features, and the entire memory footprint of the model rapidly adds up. Of course, we may reduce either the hash size, the embedding dimension, the precision, or all of these, but this may result in a hit in modeling accuracy.
Fundamentally, then, embedding tables introduce a memory bottleneck: we can only add as many sparse features to our model as we have memory on our GPUs. This limitation incentives the search for novel sparse feature encoding paradigms, one of which being “Deep Hash Embedding” (DHE), introduced in Kang et al 2021.
Deep Hash Embedding architecture

The key idea behind DHE is to replace embedding tables with an encoder-decoder architecture that has a much smaller (75% in their experiments) memory footprint.
Under the hood, this works as follows: in the encoding step, we map the input id into a dense, k-dimensional feature vector using k hash functions that are normalized to the range -1 to 1, resulting in a dense, random vector. In the decoding step, we pass this dense vector through a small neural network that learns to map the random vector into a semantically meaningful embedding.
In short, DHE replaces a shallow and wide neural network (i.e., the embedding table) with a deep and narrow neural network. This has two main advantages:
first, no hash collisions, due to the use of a large number of hash functions k, e.g. k=1024.
second, low memory footprint, due to not having to store the embedding for each hash in the hash space. For example, with an embedding dimension of 32, a DHE module with 3 hidden layers with internal dimension of 1800 has 75% fewer parameters compared to a standard embedding table with a hash size of 2M.
Theoretical properties of dense hash encoding
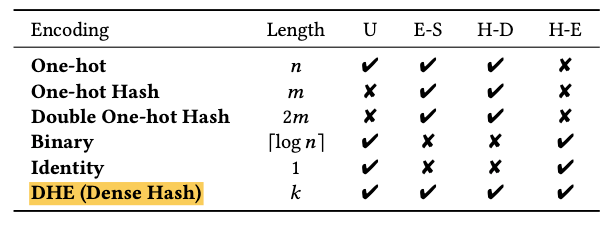
The use of a large number of hash functions normalized to produce a dense vector is a novelty introduced in this work. Theoretically, this dense hash encoding scheme has a number of attractive properties compared to alternatives, namely:
Uniqueness: this means that no two ids share the same embedding. In DHE, this can be guaranteed by choosing k to be large enough: the authors use k=1024.
Equal Similarity: any two encodings should be equally similar, which in DHE is guaranteed because we use a new random hash in each dimension. A counter-example of this property is binary hashing, where hash(9)=[1,0,0,1] is more similar to hash(8)=[1,0,0,0] than hash(7)=[0,1,1,1]. This artificial similarity could cause the model to overfit.
High Dimensionality: the encoded vector needs to have a dimension that’s high enough for the downstream model to learn anything meaningful, which again in DHE can be guaranteed by choosing k sufficiently large. A counter-example is identity encoding, where we simply pass the raw id directly into the model: in the extreme case, the model may simply overfit to the relationship between the id itself and the target.
High Shannon Entropy: each dimension in the encoded space should have high entropy, i.e. a large amount of information encoded along that dimension. In DHE, this is guaranteed because the hash vector is dense. A counter-example is one-hot encoding, where any particular dimension will be almost always zero, hence having low entropy. Low entropy is undesirable because this means that we’re not using memory in an optimal way: DHE’s superior memory budgeting boils down to its higher Shannon Entropy.
The dense hash encoding scheme in DHE, in summary, checks all 4 of these boxes, while other algorithms such as one-hot or binary encoding only check some of them.
Experimental results
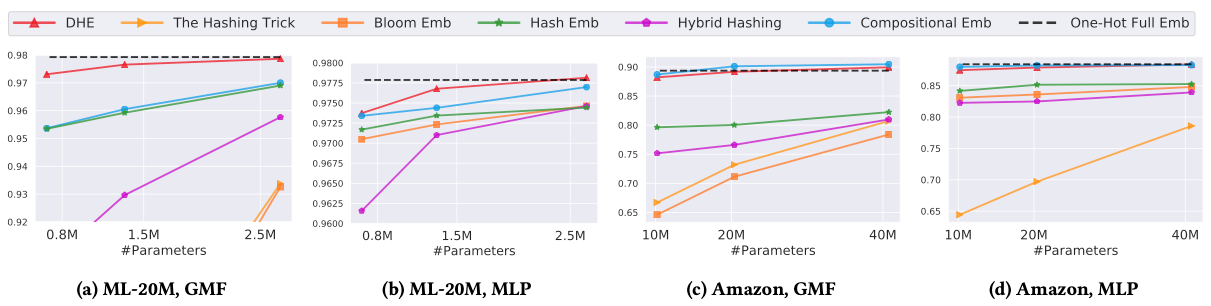
The authors evaluated the performance of DHE under multiple conditions:
using two different backbone models: MLP = a deep neural network, and GMF = a generalized matrix factorization model,
two different datasets: MovieLens-20M (movie rating prediction) and Amazon (e-commerce shopping prediction),
against 5 competing algorithms and a baseline that simply applies one-hot encoding to all ids without any hashing (the black dashed line in the figure).
over a range of GPU memory budgets from 10M to 40M model parameters on the Amazon dataset and 0.7 to 2.6M parameters on the MovieLens dataset.
The result is that DHE performs on par or better than the competing algorithms across datasets and model backbones, and works particularly well for small memory budgets, for which other algorithms may introduce too many hash collisions: in short, DHE has the most flat curve of modeling accuracy vs memory budget. On both datasets, the DHE-based model can be shrunk to around a quarter of its size without large performance degradations.
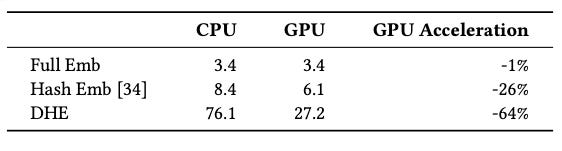
However, by design DHE comes at a cost of increased latency: we can’t simply look up embeddings any more, we have to compute them using the encoder-decoder architecture. The authors estimate DHE is about 9x slower than full embedding (without hashing), and 4.5x slower than hash-based embedding tables.
Take-away
DHE is a theoretically interesting idea, and the promise of zero hash collisions with low memory footprint could turn out to be practically useful in certain applications. However, certain hurdles remain:
Inference. Embedding tables provide O(1) embedding lookup, and DHE cannot compete with that. Keeping everything else fixed, a DHE-based system would have a lower memory footprint but higher latency. That said, it would be interesting to see if the freed up memory in DHE could be re-invested, e.g. into a larger batch size, to compensate for the latency hit.
Multi-valency. In the paper, the authors only showed the results for DHE on single-valent features, i.e. user ids and item ids. Expanding DHE to multi-valent features such as user engagement histories comes with the additional challenge of having to pass each individual item through DHE’s MLP, which can further degrade latency with a computational complexity that’s linear with the history length.
Training stability. Training embedding tables is a practice that been well established in the industry, but the encoder/decoder architecture proposed here comes with new training challenges. The authors of DHE remark that training the deep decoding network is “quite challenging”, and that one-hot based shallow networks are much easier to train. They had to apply several tricks such as Mish activation and Batch Norm to get it to work for this particular work, but there’s no guarantee that this recipe works elsewhere. Indeed, Tsang et al 2023 found inferior performance of DHE compared to competing algorithms on a different dataset.
Embedding tables aren’t going to go away any time soon. Deep Hash Embedding may just be a theoretical curiosity for now, but this could change as models become larger than ever before — and GPUs not any cheaper.